Data Analytics
Erhalte deine App-Metriken von der Application Cloud
Wo sind meine Metriken? Eine Cloud Foundry Geschichte.
Data Analytics
Wo sind meine Metriken? Eine Cloud Foundry Geschichte.
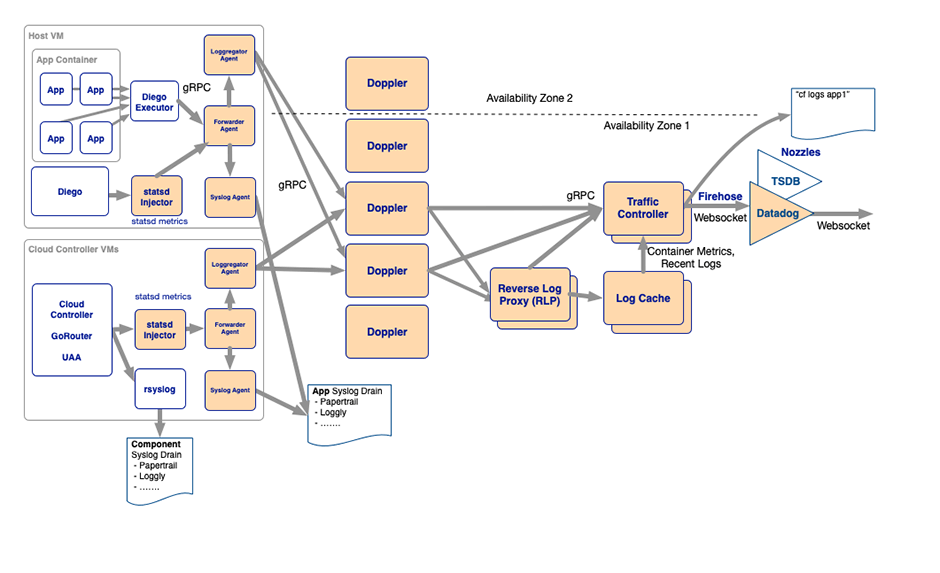
Der Loggregator in Cloud Foundry ist das System hinter den Kulissen, das für das Sammeln und Streamen von Protokollen und Metriken über Benutzeranwendungen verantwortlich ist. Er sammelt und streamt auch Metriken von Cloud Foundry-Komponenten selbst und Zustandsdaten von anderen Plattform-VMs. Mit Loggregator kannst du diese Logs und Metriken entweder über die Loggregator CF-CLI-Plugins(öffnet ein neues Fenster) oder über verschiedene Dienste und Verbraucher von Drittanbietern einsehen, z. B. den Cloud-Controller (API), eine Firehose Nozzle oder einen Log-Cache-Endpunkt.
Der Loggregator verwendet eine Microservice-Architektur, die Komponenten zum Sammeln, Speichern und Weiterleiten von Logs und Metriken umfasst:
Weitere Informationen über das Loggregator-System insgesamt:
https://docs.developer.swisscom.com/loggregator/architecture.html(öffnet ein neues Fenster)
https://docs.developer.swisscom.com/loggregator/container-metrics.html(öffnet ein neues Fenster)
Von allen Komponenten, aus denen das Loggregator-System besteht, ist der Log-Cache für unseren Anwendungsfall am interessantesten.
Log-Cache ist ein In-Memory-Speicher, mit dem du die Logs und Metriken von Loggregator über eine bestimmte Frist hinweg einsehen kannst. Log-Cache umfasst API-Endpunkte und ein CF-CLI-Plugin(öffnet ein neues Fenster) zum Abfragen und Filtern von Logs und Metriken. Die Log-Cache-API-Endpunkte sind standardmäßig verfügbar. Weitere Informationen über die direkte Nutzung der Log-Cache-API findest du auf GitHub unter Log-Cache(öffnet ein neues Fenster).
Der Reverse Log Proxy (RLP) in Cloud Foundry dient dazu, Logs und Metriken von den Dopplern zu sammeln und an den Log-Cache weiterzuleiten. Außerdem verfügt er über ein RLP-Gateway, über das sich externe Clients (d. h. du oder deine App) mit ihm verbinden und Ingest-Envelopes (Logs und Metriken) von der Loggregator-API streamen können.
Dieser API-Endpunkt ist in der Regel unter "log-stream." verfügbar.
Für die Swisscom AppCloud wäre dies zum Beispiel "https://log-stream.lyra-836.appcloud.swisscom.com" (und "https://log-stream.scapp-console.swisscom.com" für die interne AppCloud)
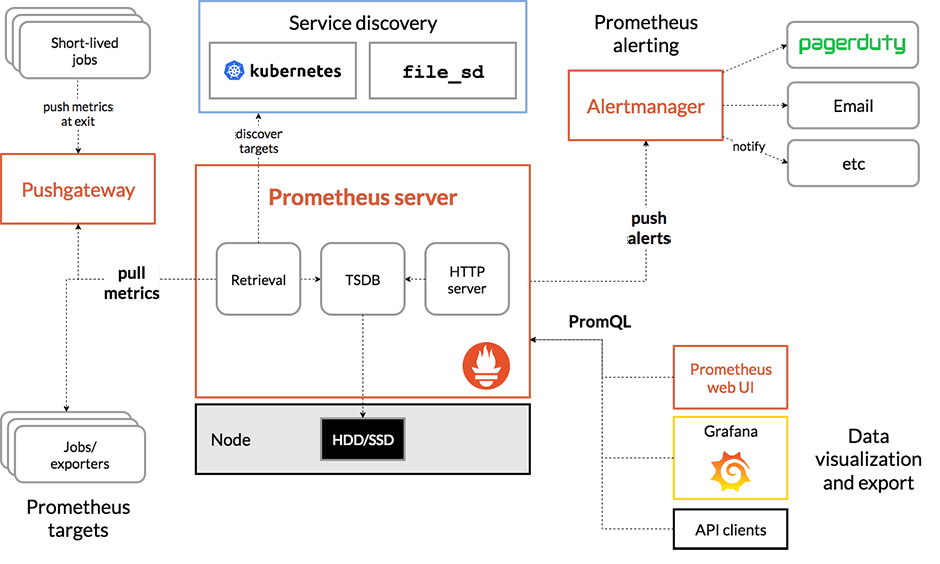
Prometheus(öffnet ein neues Fenster) ist ein System zur Ereignisüberwachung und Alarmierung. Es zeichnet Echtzeit-Metriken in seiner eigenen Zeitreihen-Datenbank mit flexiblen Abfragen und Echtzeit-Warnungen auf.Es basiert auf einem PULL-Modell, bei dem Metriken von verfügbaren Remote-"/metrics"-Endpunkten abgefragt werden. Es wird häufig als Hauptüberwachungssystem für native Cloud-Anwendungen eingesetzt.
Überblick über die Architektur:
Prometheus und Log-Cache sind großartig, aber wie bringe ich sie jetzt dazu, zusammenzuarbeiten?
Da Prometheus auf einem PULL-Modell basiert, musst du irgendwie einen "/metrics"-Endpunkt für Prometheus bereitstellen, der abgefragt werden kann. An dieser Stelle kommt der "paas-prometheus-exporter(öffnet ein neues Fenster)" ins Spiel.
Es ist eine einfache App, die du auf Cloud Foundry pushen kannst. Sie verbindet sich dann mit der API, um alle deine Apps automatisch zu erkennen, sammelt ihre Metriken von Loggregator / Log-Cache für dich und stellt sie an einem Prometheus-kompatiblen "/metrics"-Endpunkt bereit.
Wenn du ein Golang-Entwickler bist, kannst du dank der mitgelieferten go-loggregator-Bibliothek(öffnet ein neues Fenster), mit der du die Logs und Metriken von Cloud Foundry (siehe Beispiele(öffnet ein neues Fenster)) über den Reverse Log Proxy einlesen kannst, ganz einfach eine eigene App schreiben, die dies tut.
Aber jetzt wollen wir erst einmal den paas-prometheus-exporter verwenden, um unsere Metriken zu erhalten.Zuerst musst du einen neuen technischen Benutzer erstellen, der über die AppCloud Portal UI verwendet wird.Diesem neuen Benutzer kannst du dann die Rollen OrgAuditor und SpaceAuditor für alle Orgs und/oder Spaces zuweisen, von denen er App-Metriken sammeln soll.
Nach der Veröffentlichung erkennt die Exporter-App automatisch alle anderen Apps dieser Organisationen/Räume und sammelt deren Metrik-Informationen aus dem Log-Cache, um sie dir über ihren eigenen /metrics-Endpunkt zu präsentieren.
Du kannst dann deinen Prometheus so konfigurieren, dass er die Metriken von dort abruft. Ein Beispiel für die manifest.yml und Anweisungen, wie du die App pushen/konfigurieren kannst, findest du in der Readme-Datei.
Die folgenden Metriken werden für jede Anwendungsinstanz exportiert:
| Name | Type | Description |
| cpu | gauge | CPU utilisation in percent (0-100) |
| disk_bytes | gauge | Disk usage in bytes |
| disk_utilization | gauge | Disk utilisation in percent (0-100) |
| memory_bytes | gauge | Memory usage in bytes |
| memory_utilization | gauge | Memory utilisation in percent (0-100) |
| crash | counter | Increased by one if the application crashed for any reason |
| requests | counter | Number of requests processed broken down by status_range label |
| response_time | histogram | Timing of processed requests broken down by status_range label |
Lass uns jetzt ein Test-Setup mit Prometheus und Grafana in der appCloud einrichten, um zu sehen, wie es genutzt werden kann.
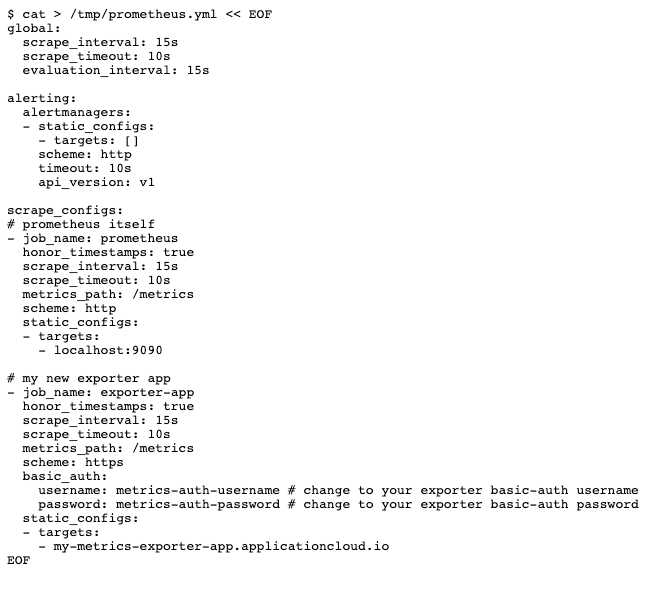
Zuerst bereiten wir eine Konfigurationsdatei für Prometheus vor:
Und führe sie dann lokal in einem Docker-Container aus:
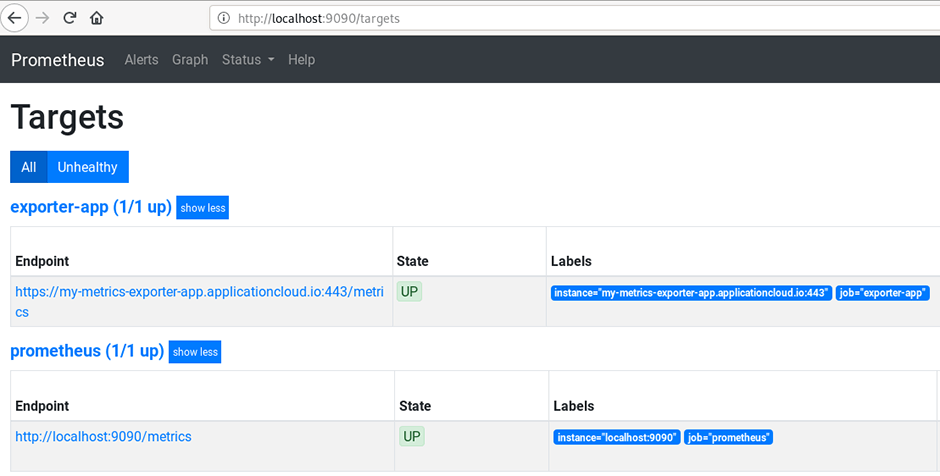
Jetzt können wir auf die Prometheus-Benutzeroberfläche zugreifen und überprüfen, ob unser Scrape-Ziel richtig funktioniert:
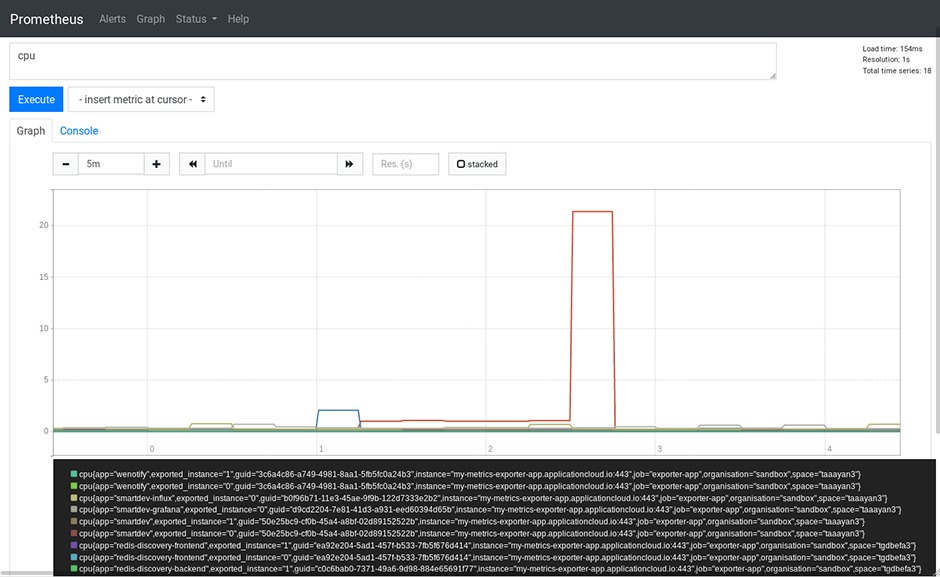
Um zu überprüfen, ob wir jetzt wirklich Metriken von unseren Apps scrappen und Live-Daten von Cloud Foundry erhalten, können wir die CPU-Metriken in Prometheus abfragen:
Success!??
Wir haben jetzt ein funktionierendes Prometheus-Setup, bei dem unsere Prometheus-Exporter-App dafür zuständig ist, Anwendungsmetriken zu sammeln und über ihren /metrics-Endpunkt an Prometheus zu übermitteln.Jetzt können wir auch darüber nachdenken, mit Grafana schöne Dashboards zu erstellen oder mit dem Prometheus Alert Manager Alarme auszulösen.
Wenn du ein interner AppCloud-Kunde von Swisscom bist, empfiehlt es sich, die CoMo-Plattform (Continuous Monitoring, Wiki-Link(öffnet ein neues Fenster)) zu nutzen und dein verwaltetes Prometheus/Grafana von dort zu beziehen.

Senior Cloud Engineer
Finde deinen Job oder die Karrierewelt, die zu dir passt. In der du mitgestalten und dich weiterentwickeln willst.
Was du draus machst, ist was uns ausmacht.