Machine Learing
L'apprendimento automatico alla frontiera
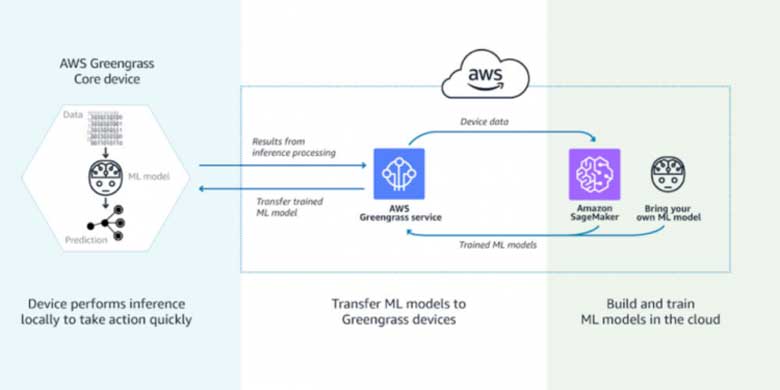
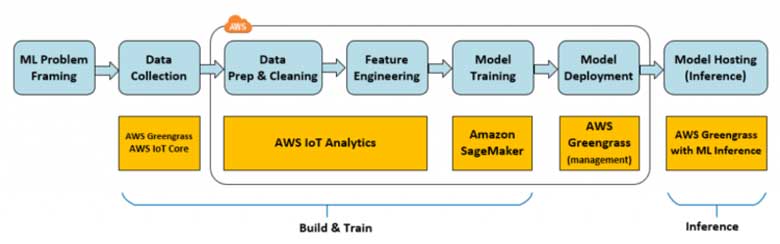
Secondo uno studio di Gartner, l'intelligenza artificiale (AI) sarà la tendenza numero 1 dell'IoT nei prossimi 5 anni. Il numero di dispositivi IoT passerà da 14,2 miliardi nel 2019 a 25 miliardi nel 2021. Il valore dell'intelligenza artificiale in questo contesto risiede nella sua capacità di ottenere rapidamente informazioni dai dati dei dispositivi. L'apprendimento automatico (ML), una tecnologia di AI, consente di riconoscere automaticamente gli schemi e di individuare le anomalie nei dati generati da sensori e dispositivi intelligenti - informazioni come temperatura, pressione, umidità, qualità dell'aria, vibrazioni e rumore. Rispetto agli strumenti di BI tradizionali, gli approcci ML possono fare previsioni operative fino a 20 volte più velocemente e con maggiore precisione.