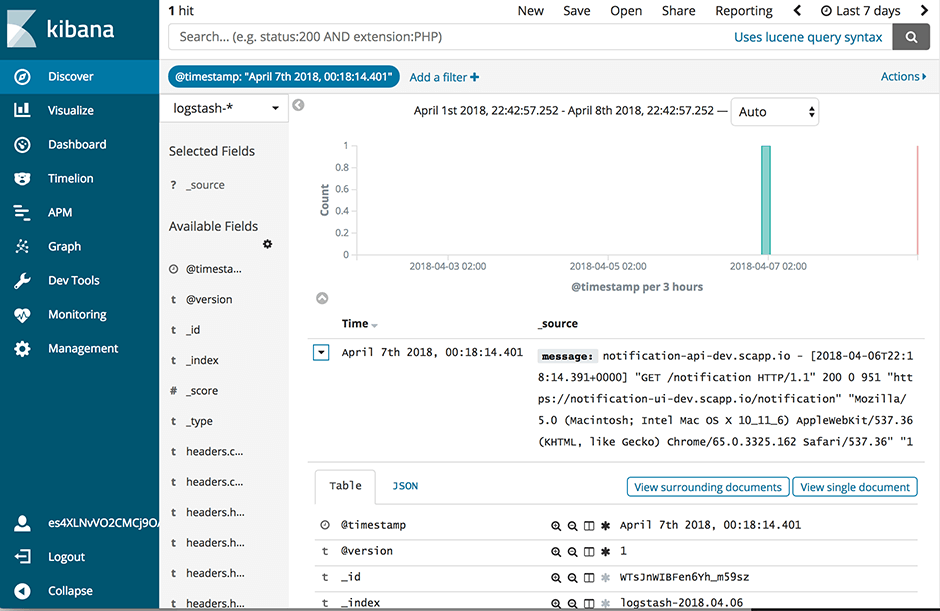
L'ancien service ELK disposait d'un filtre qui analysait les messages de log et
- extrayait les champs selon la spécification du protocole Syslog(ouvre une nouvelle fenêtre)
- extrayait les messages contenant des objets JSON en fonction des JSON
-Divise les noms d'attributs en champs
Il y avait aussi une configuration Curator(ouvre une nouvelle fenêtre) qui permettait de nettoyer Elasticsearch à intervalles réguliers. Nous décrirons les détails de la configuration de Curator dans un futur article.
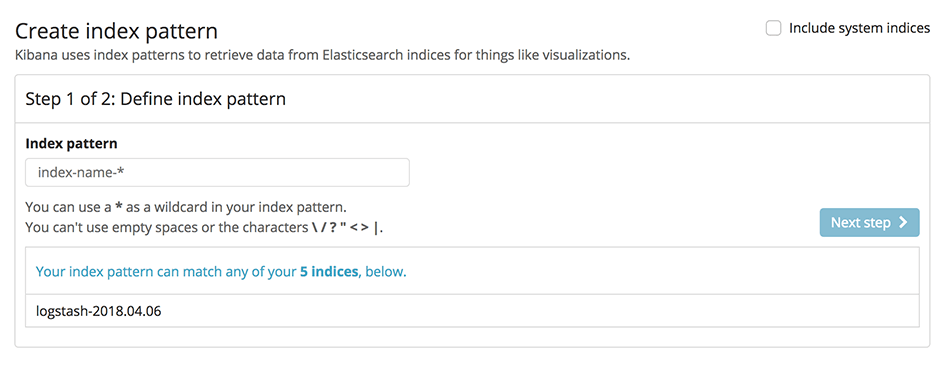
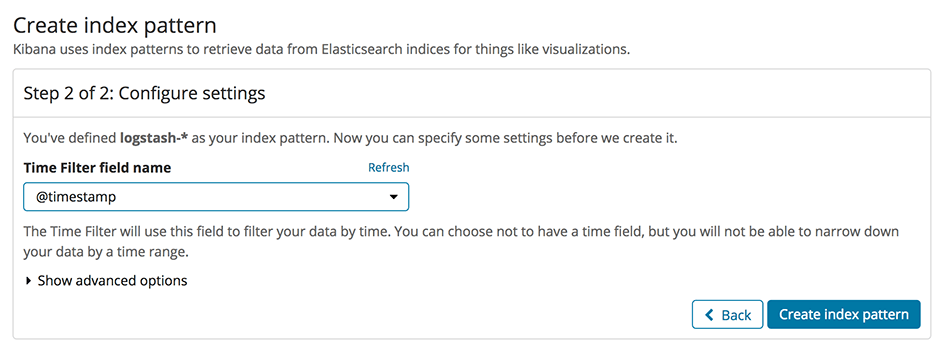
Avant de commencer la configuration des filtres, tu dois savoir que tu peux trouver les modèles des fichiers de configuration ci-dessous(ouvre une nouvelle fenêtre) sur Github. Il s'agit de modèles, car tu dois remplacer certains paramètres, comme le nom d'hôte Elasticsearch de ton instance et les données d'accès, par les valeurs correspondantes de ton environnement.
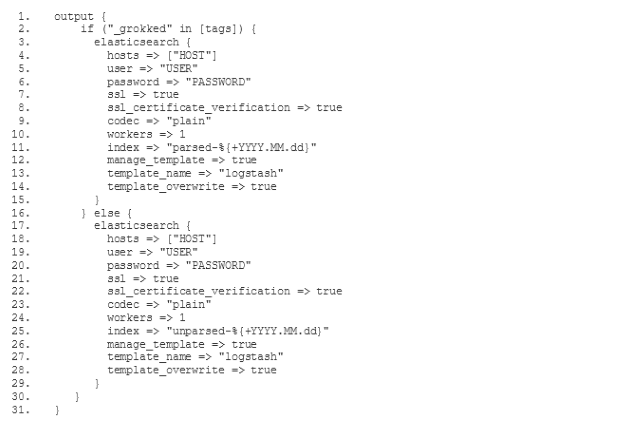
Pour configurer notre nouvelle pile ELK de manière à ce qu'elle traite les logs de la même manière que l'ancienne ELK, nous devons choisir le mode de configuration mixte, décrit dans la documentation du buildpack Logstash(ouvre une nouvelle fenêtre). Avant tout, nous devons définir notre propre configuration de filtre et de sortie. Pour cela, nous ajoutons deux nouveaux sous-répertoires conf.d et grok-patterns au répertoire dans lequel nous avons établi notre configuration Logstash. Nous ajoutons également les fichiers filter.conf, output.conf et grok-patterns dans ces répertoires comme suit :