Data Science
Environnement HANA XSA: Graph Pattern Matching
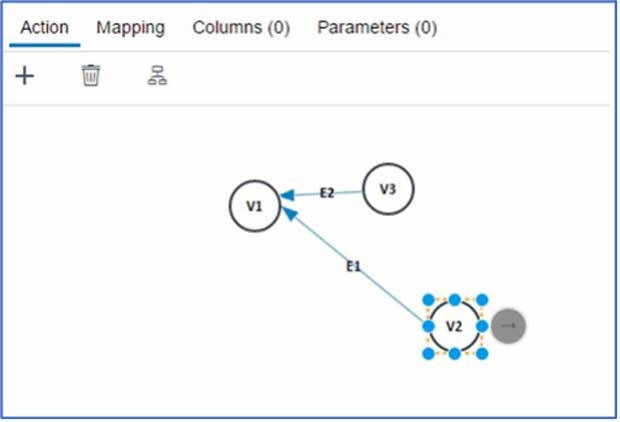
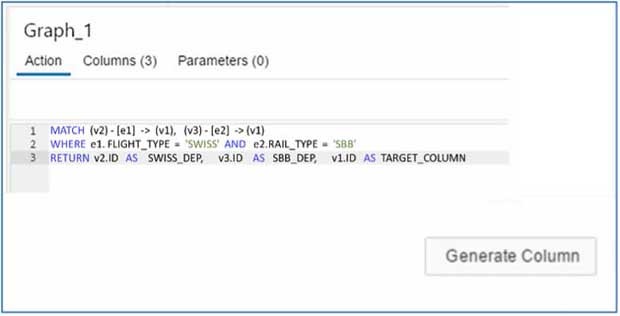
Le pattern matching est un type d'interrogation de graphes qui aide à comprendre les relations, à reconnaître les modèles et à trouver les sous-graphes qui correspondent au modèle donné. Les modèles sont une combinaison d'arêtes et de nœuds. Un nœud est une destination ou une source d'une arête. Par exemple, tu peux prendre un train CFF (attribut d'une arête) de Berne (sommet) à Zurich (sommet). Maintenant, pour agrandir le tout, il y a beaucoup de destinations, beaucoup d'itinéraires et différents moyens de transport. Il est souvent nécessaire de faire des calculs complexes pour trouver tous les modèles pour la question posée. Ce blog donne un aperçu des possibilités d'effectuer la correspondance des modèles avec des méthodes HANA natives comme une vue de calcul. Ce blog décrit en détail à la fois une méthode visuelle et une méthode de code pour la comparaison de modèles.