Data Analytics
Obtiens les métriques de ton application à partir du cloud d'application
Où sont mes métriques? Une histoire de Cloud Foundry.
Data Analytics
Où sont mes métriques? Une histoire de Cloud Foundry.
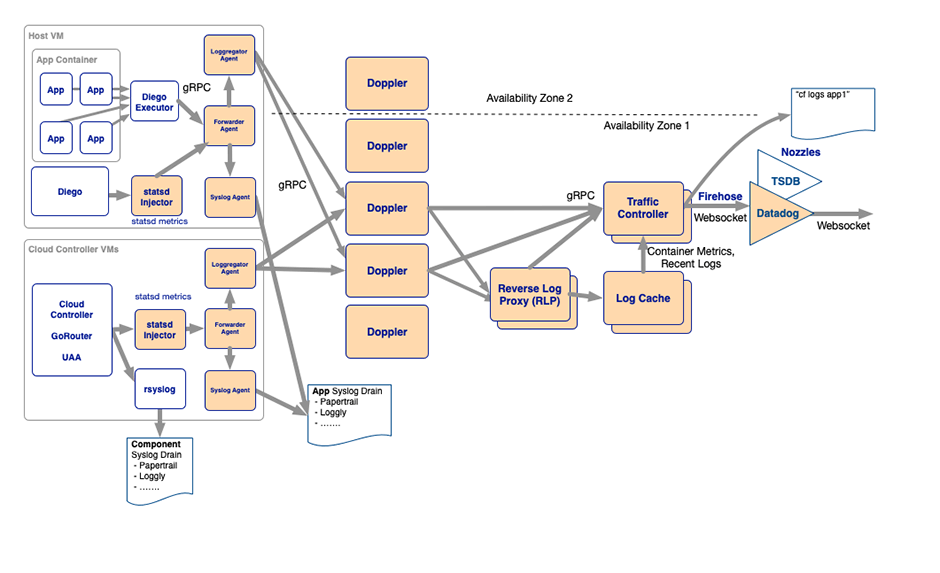
L'agrégateur de logs dans Cloud Foundry est le système en coulisses responsable de la collecte et du streaming des journaux et des métriques sur les applications des utilisateurs. Il collecte et diffuse également des métriques des composants Cloud Foundry eux-mêmes et des données d'état d'autres VM de plateforme. Avec Loggregator, tu peux consulter ces logs et métriques soit via les Loggregator CF-CLI-Plugins(ouvre une nouvelle fenêtre) ou consulter différents services et consommateurs tiers, par exemple le contrôleur de cloud (API), un Firehose Nozzle ou un point final de cache de log.
L'agrégateur de logs utilise une architecture de microservices qui comprend des composants pour collecter, stocker et transmettre les logs et les métriques:
Plus d'informations sur l'ensemble du système Loggregator:
https://docs.developer.swisscom.com/loggregator/architecture.html(ouvre une nouvelle fenêtre)
https://docs.developer.swisscom.com/loggregator/container-metrics.html(ouvre une nouvelle fenêtre)
Parmi tous les composants qui composent le système loggregator, le cache de log est le plus intéressant pour notre cas d'utilisation.
Le cache de log est un stockage en mémoire qui te permet de consulter les logs et les métriques de Loggregator pendant un certain délai. Le cache de log comprend les points finaux de l'API et un CF-CLI-Plugin(ouvre une nouvelle fenêtre) pour interroger et filtrer les logs et les métriques. Les points finaux de l'API Log Cache sont disponibles par défaut. Tu trouveras plus d'informations sur l'utilisation directe de l'API Log Cache sur GitHub à l'adresse suivante Log-Cache(ouvre une nouvelle fenêtre).
Le Reverse Log Proxy (RLP) de Cloud Foundry sert à collecter les logs et les métriques des dopplers et à les transmettre au cache des logs. Il dispose également d'une passerelle RLP qui permet aux clients externes (c'est-à-dire toi ou ton application) de s'y connecter et de diffuser des développements ingest (logs et métriques) depuis l'API Loggregator.Ce point final de l'API se trouve généralement sous "log-stream." est disponible.Pour l'AppCloud de Swisscom, ce serait par exemple "https://log-stream.lyra-836.appcloud.swisscom.com" (et "https://log-stream.scapp-console.swisscom.com" pour l'AppCloud interne)
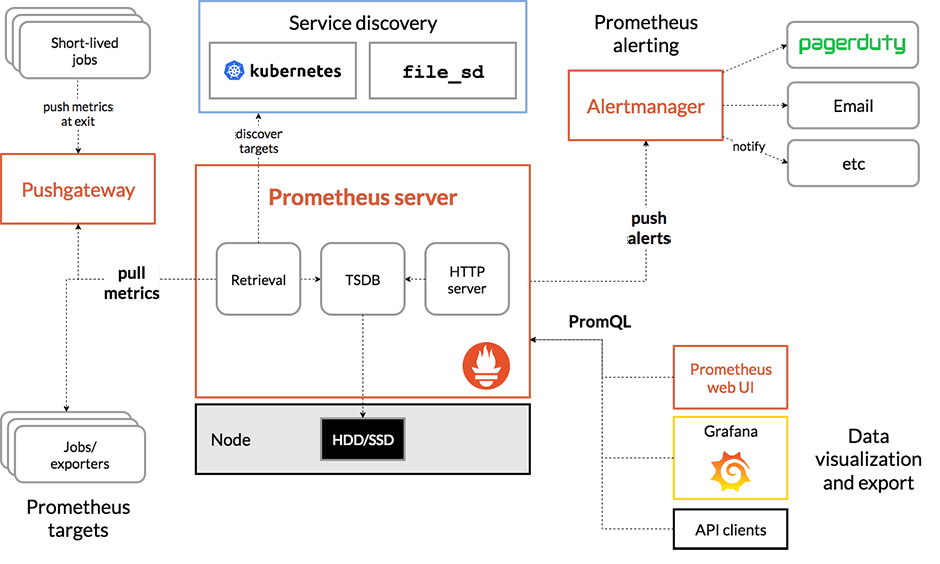
Prometheus(ouvre une nouvelle fenêtre) est un système de surveillance des événements et d'alerte. Il enregistre les métriques en temps réel dans sa propre base de données de séries temporelles avec des requêtes flexibles et des alertes en temps réel.Il est basé sur un modèle PULL, dans lequel les métriques sont interrogées à partir de points de terminaison "/metrics" distants disponibles. Il est souvent utilisé comme système de surveillance principal pour les applications cloud natives.
Aperçu de l'architecture:
Prometheus et Log-Cache sont géniaux, mais comment les faire travailler ensemble maintenant?
Comme Prometheus est basé sur un modèle PULL, tu dois d'une manière ou d'une autre fournir à Prometheus un point final "/metrics" qui peut être interrogé. C'est là qu'intervient le "paas-prometheus-exporter(ouvre une nouvelle fenêtre)" dans le jeu.
C'est une application simple que tu peux pousser sur Cloud Foundry. Elle se connecte ensuite à l'API pour reconnaître automatiquement toutes tes applications, collecte leurs métriques à partir de Loggregator / Log-Cache pour toi et les met à disposition à un point final "/metrics" compatible avec Prometheus.Si tu es un développeur Golang, tu peux utiliser le logiciel inclus pour créer des applications go-loggregator-Bibliothek(ouvre une nouvelle fenêtre), avec laquelle tu peux consulter les logs et les métriques de Cloud Foundry (voir Beispiele(ouvre une nouvelle fenêtre)) via le proxy de journal inversé, il suffit d'écrire ta propre application pour le faire.
Mais pour l'instant, utilisons paas-prometheus-exporter pour obtenir nos métriques.Tout d'abord, tu dois créer un nouvel utilisateur technique qui sera utilisé via l'UI du portail AppCloud.Tu peux ensuite attribuer à ce nouvel utilisateur les rôles OrgAuditor et SpaceAuditor pour tous les orgs et/ou espaces dont il devra collecter les métriques d'app.
Après la publication, l'application Exporter détecte automatiquement toutes les autres applications de ces organisations/espaces et collecte leurs informations sur les métriques à partir du cache du journal pour te les présenter via son propre point d'accès /metrics.Tu peux ensuite configurer ton Prometheus pour qu'il récupère les métriques à partir de là. Tu trouveras un exemple de manifest.yml et des instructions sur la façon de pousser/configurer l'application dans le fichier readme.
Les métriques suivantes sont exportées pour chaque instance d'application:
| Name | Type | Description |
| cpu | gauge | CPU utilisation in percent (0-100) |
| disk_bytes | gauge | Disk usage in bytes |
| disk_utilization | gauge | Disk utilisation in percent (0-100) |
| memory_bytes | gauge | Memory usage in bytes |
| memory_utilization | gauge | Memory utilisation in percent (0-100) |
| crash | counter | Increased by one if the application crashed for any reason |
| requests | counter | Number of requests processed broken down by status_range label |
| response_time | histogram | Timing of processed requests broken down by status_range label |
Installons maintenant une configuration test avec Prometheus et Grafana dans appCloud pour voir comment il peut être utilisé.
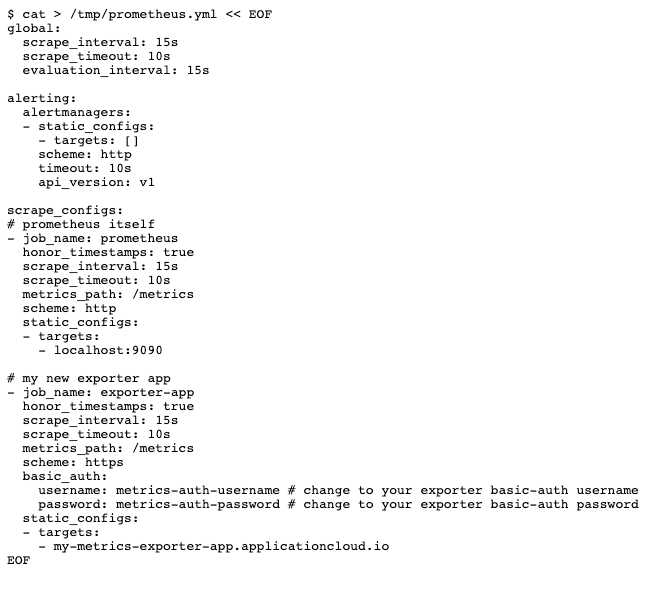
Tout d'abord, nous préparons un fichier de configuration pour Prometheus:
Et exécute-les ensuite localement dans un conteneur Docker:
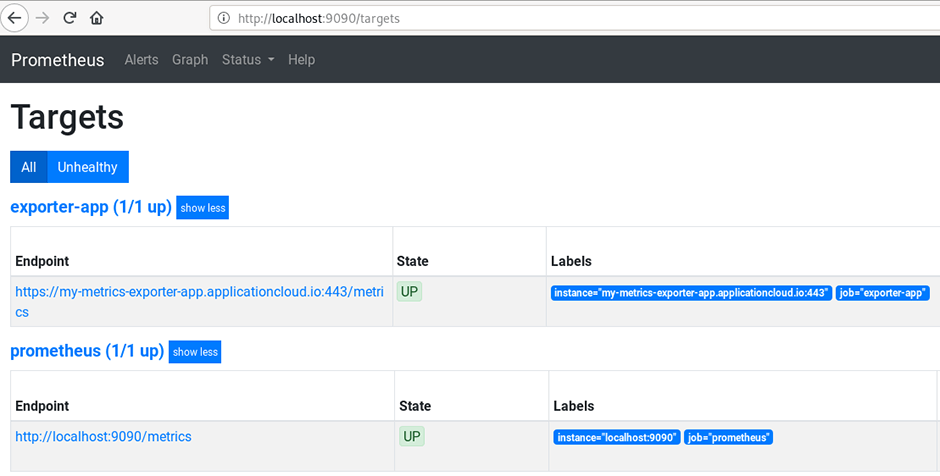
Maintenant, nous pouvons accéder à l'interface utilisateur de Prometheus et vérifier que notre cible de scrap fonctionne correctement:
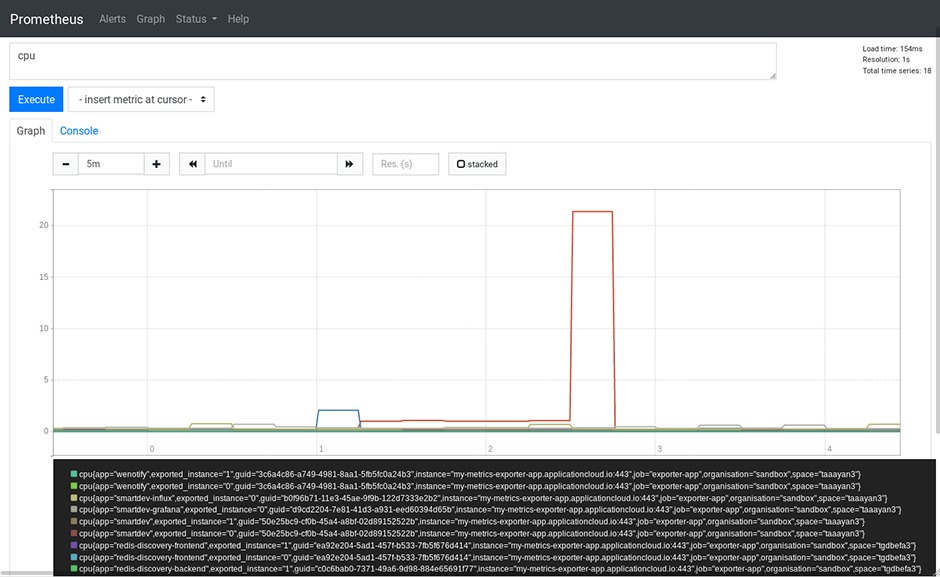
Pour vérifier si nous scrappons vraiment les métriques de nos apps maintenant et si nous obtenons des données en direct de Cloud Foundry, nous pouvons interroger les métriques du CPU dans Prometheus:
Success!??
Pour vérifier si nous scrappons vraiment les métriques de nos apps maintenant et si nous obtenons des données en direct de Cloud Foundry, nous pouvons interroger les métriques du CPU dans Prometheus:
Si tu es un client AppCloud interne de Swisscom, il est recommandé d'utiliser la plateforme CoMo (Continuous Monitoring, Wiki-Link(ouvre une nouvelle fenêtre)) et d'obtenir ton Prometheus/Grafana géré à partir de là.

Senior Cloud Engineer
Trouve le Job ou l’univers professionnel qui te convient. Où tu veux co-créer et évoluer.
Ce qui nous définit, c’est toi.