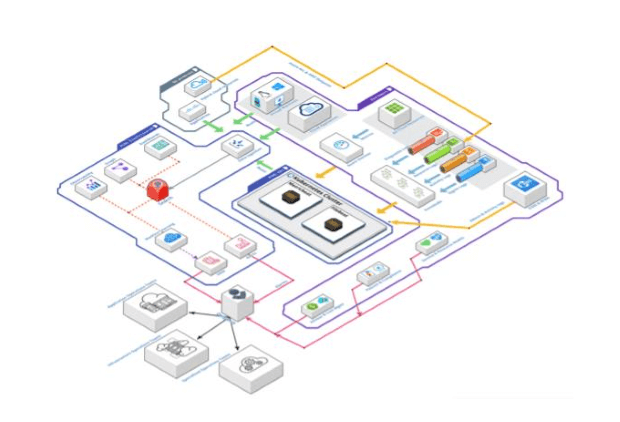
Le premier niveau, la télémétrie, se trouve en haut à droite. Il s'agit des sources de données de nos clients cloud public, comme les différents types de protocoles des ressources cloud PaaS et SaaS, par exemple les journaux d'activité ou les protocoles de connexion collectés avec EventHub, et leurs métriques collectées par Azure Monitor. De plus, les ressources IaaS envoient leurs métriques et leurs protocoles directement à notre pile Elastic à l'aide d'agents Beats et collectent également les protocoles de gestion et d'activité des offres cloud d'O365 et M365 pour fournir des solutions d'observation et de monitoring du domaine de travail cloud. Enfin, il faut mentionner la tendance aux scénarios hybrides, dans lesquels nos clients connectent leurs différents clouds et infrastructures sur site. Nous collectons les protocoles et les métriques de certains moyens d'exploitation, parfois directement et parfois via des offres cloud publiques comme Azure Arc et AWS Outpost.