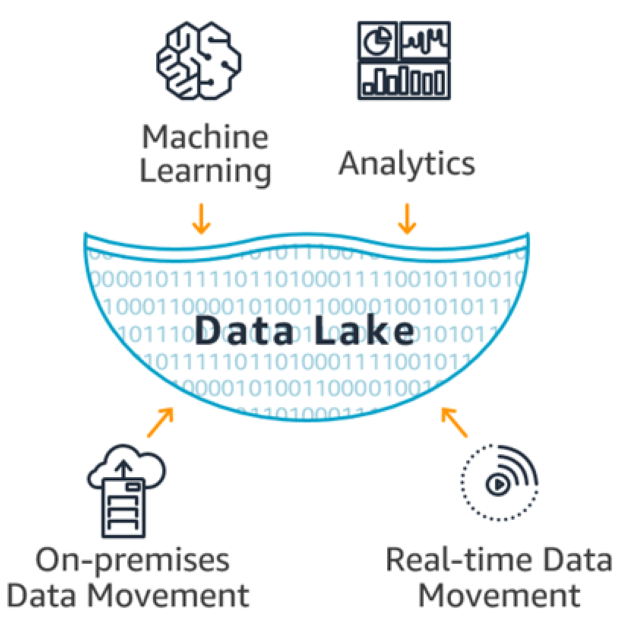
L'analyse des grandes données vise à traiter d'énormes quantités de données structurées et non structurées afin d'obtenir des informations précieuses pour l'entreprise. Elle recherche des corrélations et des modèles sous-jacents qui ne sont pas évidents pour l'homme, mais qui sont révélés par l'IA (Intelligence Artificielle), les technologies d'apprentissage automatique et les systèmes informatiques distribués.
Une deuxième transformation numérique est en cours, encore plus profonde et pertinente pour nos vies que ce que nous avons vécu au cours des dernières décennies. Cette transformation numérique ne s'occupe pas seulement de la création de services numériques, mais aussi de la transformation de tout ce que nous savons en répliques numériques (comme dans les jumeaux numériques, le métavers, l'IoT (Internet Of Things)). En particulier, l'utilisation de l'analyse des Big Data, aide à analyser toutes sortes de données qui peuvent nous aider, notre entreprise et notre vie, à s'améliorer.
Le grand catalyseur de cette véritable transformation numérique a été la pandémie, qui a forcé non seulement les entreprises, mais aussi la plupart des gens à se tenir au courant des dernières technologies numériques. Selon une enquête récente, 67% des personnes interrogées ont déclaré avoir accéléré leur transformation numérique et 63% ont augmenté leur budget numérique en raison de la pandémie [7]. Cette accélération de la transformation numérique est visible dans le secteur de la santé (rapports contrôlés par l'IA, dossiers médicaux électroniques, prévisions de pandémie, etc.), mais aussi dans de nombreux autres secteurs. L'utilisation d'analyses avancées pour comprendre les dernières tendances dues à la pandémie et au travail à distance a pris de l'importance. Les entreprises ont adapté leurs services numériques et leurs stratégies numériques à cette nouvelle réalité. C'est pour cette raison que l'on s'attend à ce que la croissance du marché numérique et de l'analytique big data soit encore plus dynamique dans les années à venir.
Il n'y a pas si longtemps, les technologies de Big Data et d'IA sont devenues populaires auprès des entreprises. Toutes les entreprises voulaient entrer dans cette nouvelle ère de connaissances intelligentes. Elles ont donc commencé à rassembler en un seul endroit toutes sortes de données commerciales traditionnelles, mais aussi des données d'appareils, des protocoles, des fichiers texte, des documents, des images, etc. Dans l'espoir que ces nouvelles technologies puissent extraire des connaissances de toutes ces grandes quantités de données avec peu d'efforts et qu'elles soient pertinentes pour les entreprises. Tout cela s'est produit, soit en raison du manque de maturité des entreprises en ce qui concerne les technologies Big Data, soit parce qu'elles n'avaient pas de stratégie Big Data clairement définie.