Data Science
Améliorations dans BW4HANA 2.0 SP04
CompositeProvider offre des fonctionnalités étendues pour fusionner les données des InfoProviders BW ainsi que pour créer des scénarios mixtes avec les vues HANA.
Data Science
CompositeProvider offre des fonctionnalités étendues pour fusionner les données des InfoProviders BW ainsi que pour créer des scénarios mixtes avec les vues HANA.
Avec SAP BW4HANA 2.0 SP04, de nombreuses nouvelles améliorations ont été incluses. Bon nombre de ces fonctionnalités existaient déjà dans les vues de calcul HANA. Néanmoins, je trouve intéressant de voir leurs alternatives BW.
Dans ce blog, les sujets suivants sont abordés. À la fin, une étude de cas simple dépeint ses cas d'utilisation:
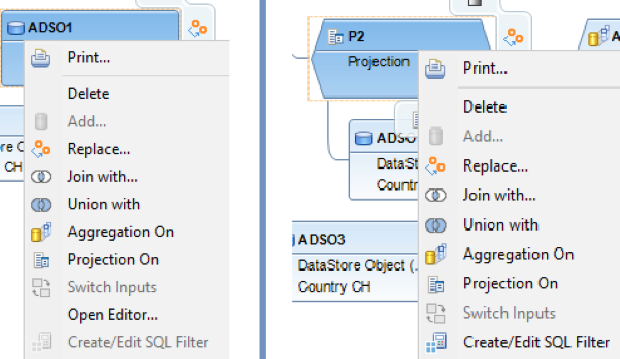
Auparavant, il n'existait pas de fonctionnalité standard pour agréger les valeurs des ratios dans la structure cible d'un CompositeProvider. Ce comportement est similaire à la fonctionnalité déjà fournie dans les vues de calcul HANA. La plupart du temps, il est nécessaire de joindre les données de plusieurs fournisseurs transactionnels sur différents états d'agrégation. Ce type d'agrégation est effectué au niveau de la base de données. La projection, quant à elle, sert principalement à définir des filtres SQL sur des PartProviders spécifiques tels que les ADSO. Pour en savoir plus, voir le sous-thème "Filtre SQL HANA".
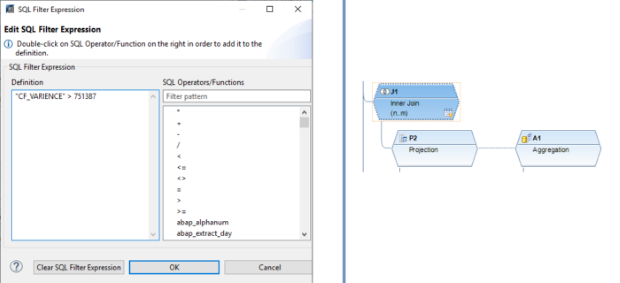
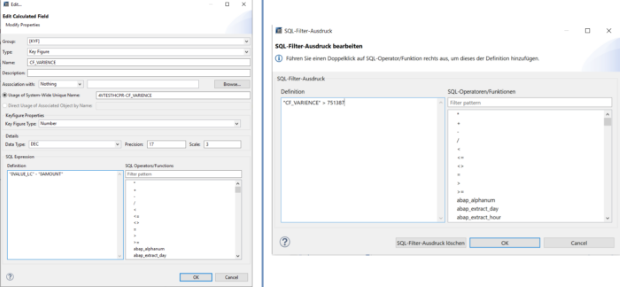
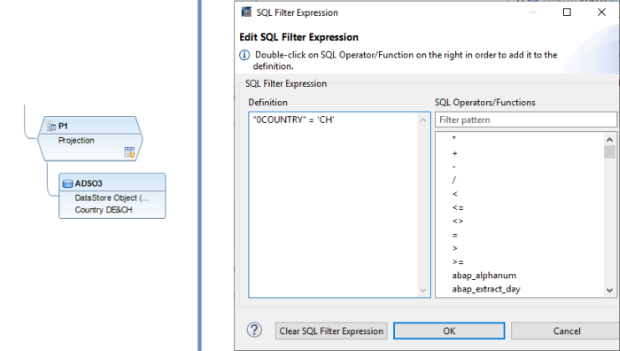
Le filtre SQL est un outil puissant qui permet de filtrer des données spécifiques de l'ensemble du CompositeProvider ou de ses PartProviders. Il permet de créer des filtres supplémentaires à différents niveaux de nœuds d'un CompositeProvider. Directement sur le nœud supérieur ou sur ses différentes parties, telles que les unions, les jointures, les projections et les agrégations spécifiques situées en dessous. Cependant, de tels filtres ne peuvent pas être définis directement sur un PartProvider. Par conséquent, un nœud d'agrégation ou de projection doit être ajouté par-dessus, afin d'activer cette fonctionnalité. Dans un filtre SQL, les champs calculés et les champs normaux peuvent être utilisés pour construire une expression. Le langage HANA SQL Script est utilisé à cette fin. Une liste des expressions disponibles s'affiche lorsqu'on les sélectionne. Il existe déjà une référence complète sur le script SQL HANA disponible ici(ouvre une nouvelle fenêtre).
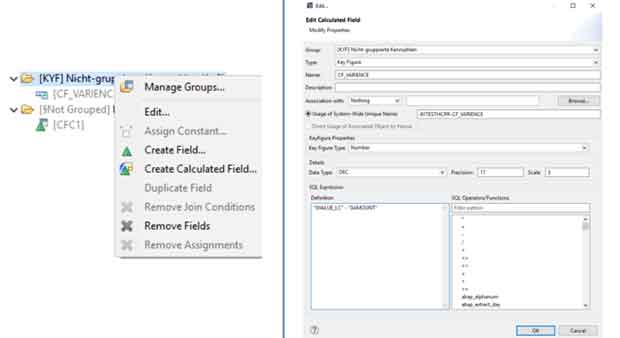
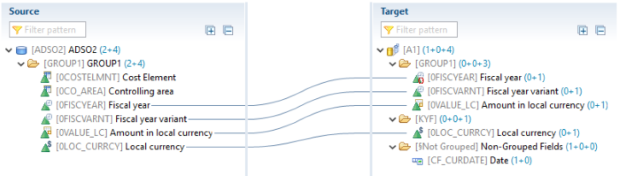
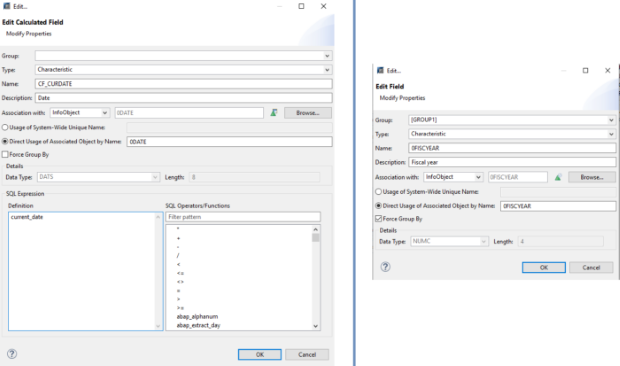
Calculations Fields est une autre fonctionnalité de la base de données HANA intégrée au CompositeProvider. Elle propose une liste d'expressions SQL. Des champs simples peuvent également être ajoutés. Tous deux peuvent être définis soit comme une caractéristique, soit comme un ratio. En tant que caractéristique, l'option "Groupe forcé" peut également être activée. Il est important de noter que dans le cas des jointures temporelles, les filtres SQL, les expressions SQL, le groupe forcé et le changement d'agrégation ne sont pas autorisés.
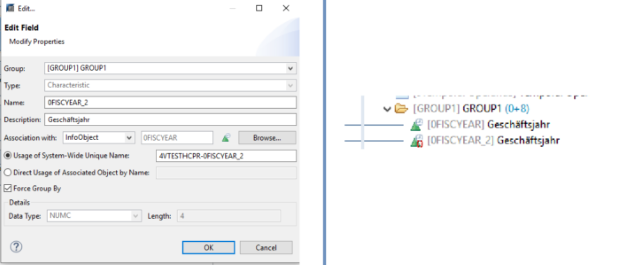
Après avoir migré de MultiProvider à CompositeProvider, la fonctionnalité de mappage croisé n'était plus prise en charge. En guise de solution de rechange, il est désormais possible de créer des champs dupliqués. Dans ce cas, un modèle est repris de l'objet d'origine avec une possibilité de dénomination personnalisée. La fonctionnalité "Forcer le Groupe par" peut maintenant être activée pour tous les champs et toutes les caractéristiques. Un symbole apparaît pour indiquer cette fonctionnalité.
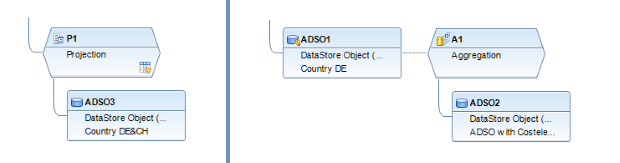
Notre exemple de mise en œuvre comprend 3 ADSO transactionnels (Data Mart) avec différents niveaux de granularité.
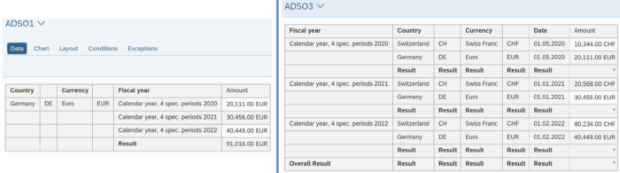
ADSO1 (DE)
ADSO3 (DE&CH)
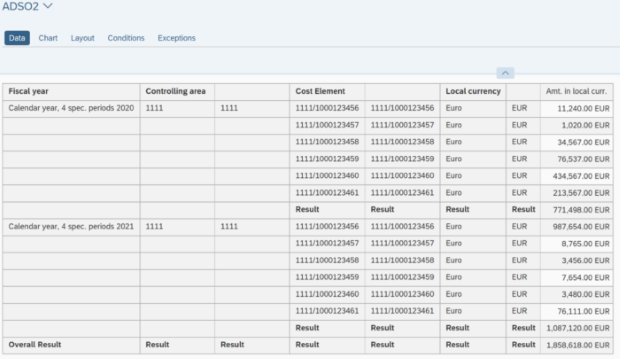
ADSO2 (Kostenarteninformationen)
Données brutes:
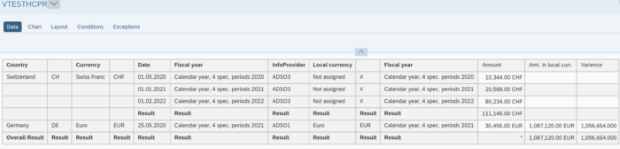
Dans cette étude de cas, nous aimerions combiner les données DE de l'ADSO1 avec les informations CH de l'ADSO3 et améliorer les données de l'ADSO1 avec les valeurs de l'ADSO2. À la fin de cette étude de cas, l'aperçu des résultats est présenté.
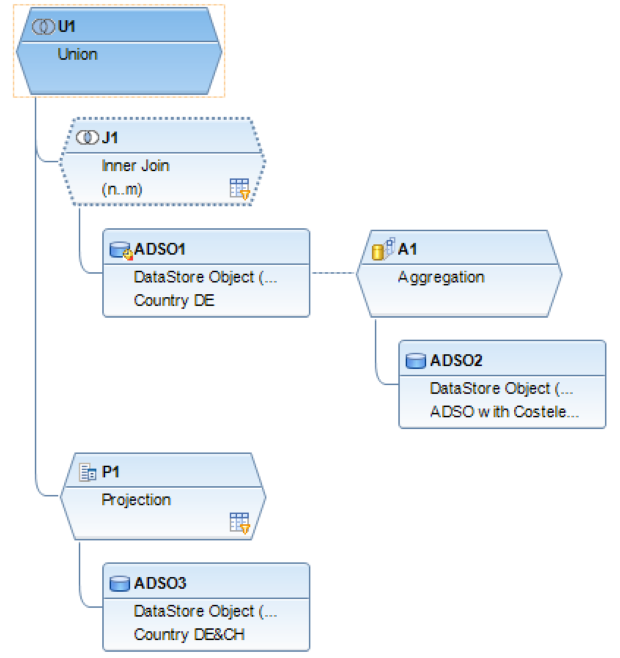
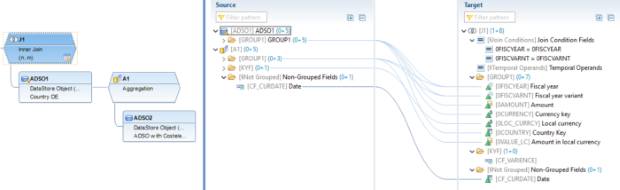
Étape 1: Étant donné que ADSO1 et ADSO2 ont une granularité différente, une agrégation supplémentaire est construite au-dessus de ADSO2. Pour cela, nous devons agréger les données d'ADSO2, supprimer les informations sur les éléments de coût et les joindre à celles d'ADSO1.
Étape 2: Dans notre exemple, nous récupérons les informations relatives à la date du jour en tant que champ de calcul, de type Caractéristique. Le "Groupe forcé par" est activé pour 0FISCYEAR.
Étape 3: ADSO1 est joint à l'agrégation d'ADSO2. Nous définissons ici un champ de calcul, de type ratio. Dans notre exemple, il s'agit d'une simple variance entre "Montant" et "Montant en LC". Au niveau de la jointure, nous utilisons ce champ de calcul pour filtrer des combinaisons de données spécifiques directement à partir de la jointure.
Étape: ADSO3 comprend à la fois des données DE et CH, afin d'éviter les doublons avec ADSO1, nous créons une projection par-dessus et utilisons le filtre SQL pour sélectionner uniquement les données CH.
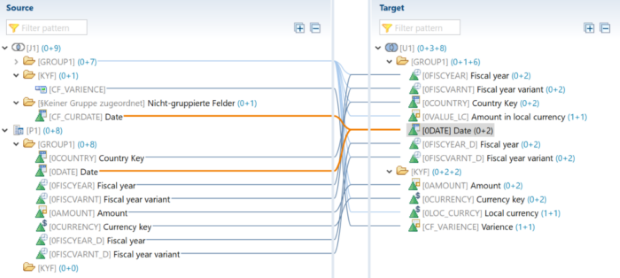
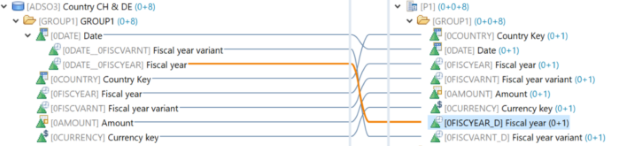
Étape 5: Dans l'Union, le champ de date d'ADSO3 est mis en correspondance avec le champ de calcul de la date actuelle de Join. Le champ en double "Année fiscale" (0FISCYEAR_D) est mappé pour ADSO3 à partir de l'attribut de navigation 0DATE et pour les autres 0FISCYEAR est pris.
Aperçu des données:

Analytics Consultant
Trouve ton travail ou le monde de la carrière qui te convient. Dans lequel tu veux participer à la création et te développer.
Ce que tu en fais, c'est ce qui nous définit.