Machine Learing
L'apprentissage automatique à la limite
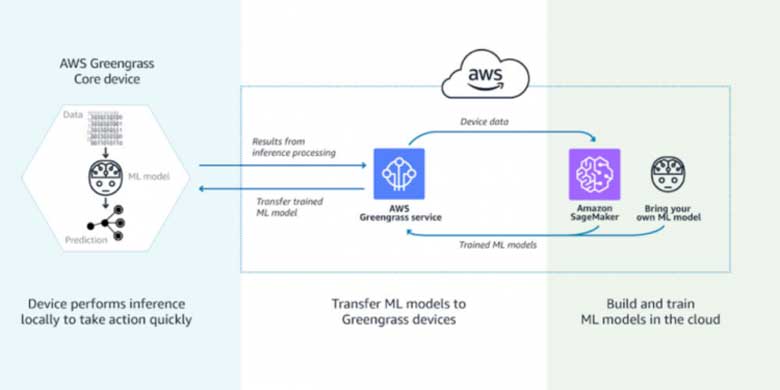
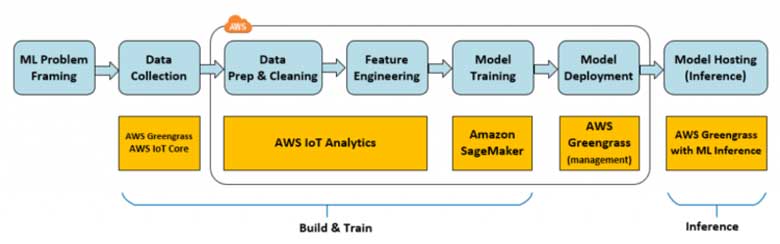
Selon une étude de Gartner, l'intelligence artificielle (IA) sera la tendance numéro 1 de l'IoT au cours des 5 prochaines années. Le nombre d'appareils IoT passera de 14,2 milliards en 2019 à 25 milliards en 2021. Dans ce contexte, la valeur de l'IA réside dans sa capacité à obtenir rapidement des connaissances à partir des données des appareils. L'apprentissage automatique (ML), une technologie d'IA, permet d'identifier automatiquement des modèles et de découvrir des anomalies dans les données générées par les capteurs et appareils intelligents - des informations telles que la température, la pression, l'humidité, la qualité de l'air, les vibrations et les bruits. Par rapport aux outils BI traditionnels, les approches ML permettent de faire des prévisions opérationnelles jusqu'à 20 fois plus rapidement et avec une plus grande précision.