Data Science
HANA XSA-Umgebung: Graph Pattern Matching
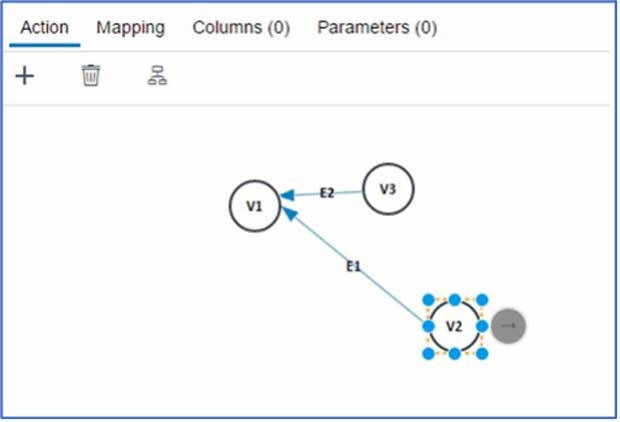
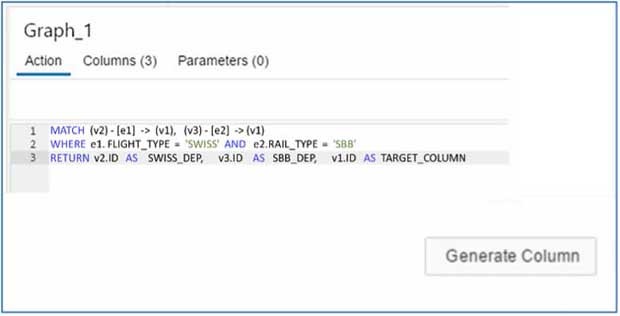
Pattern Matching ist eine Art der Graphenabfrage, die dabei hilft, Beziehungen zu verstehen, Muster zu erkennen und Teilgraphen zu finden, die dem vorgegebenen Muster entsprechen. Muster sind eine Kombination aus Kanten und Knoten. Ein Knoten ist ein Ziel oder eine Quelle einer Kante. Zum Beispiel kann man mit einem SBB-Zug (Attribut einer Kante) von Bern (Scheitelpunkt) nach Zürich (Scheitelpunkt) fahren. Um das Ganze nun zu vergrößern, gibt es viele Ziele, viele Routen und verschiedene Verkehrsmittel. Oft ist es notwendig, komplexe Berechnungen durchzuführen, um alle Muster für die gestellte Frage zu finden. Dieser Blog gibt einen Überblick über die Möglichkeiten, den Musterabgleich mit nativen HANA-Methoden wie einer Berechnungsansicht durchzuführen. In diesem Blog wird sowohl eine visuelle als auch eine Code-Methode für den Musterabgleich im Detail beschrieben.