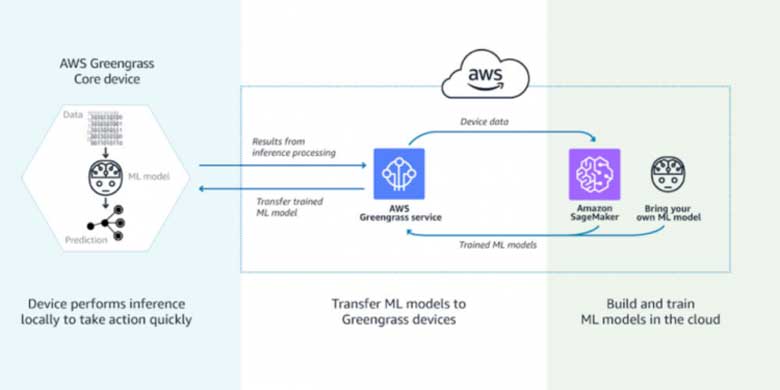
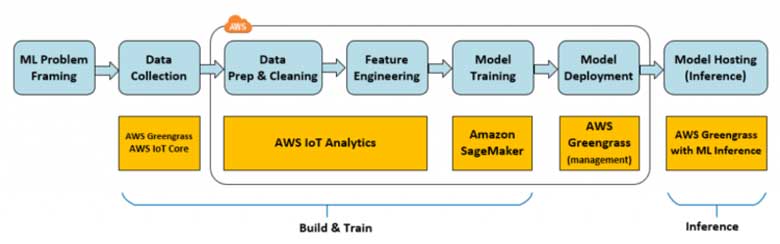
Machine Learing
Maschinelles Lernen an der Grenze
Laut einer Gartner-Studie wird künstliche Intelligenz (KI) in den kommenden 5 Jahren der Trend Nr. 1 im IoT sein. Die Zahl der IoT-Geräte wird von 14,2 Milliarden im Jahr 2019 auf 25 Milliarden im Jahr 2021 ansteigen. Der Wert der KI liegt in diesem Zusammenhang in ihrer Fähigkeit, schnell Erkenntnisse aus den Gerätedaten zu gewinnen. Maschinelles Lernen (ML), eine KI-Technologie, ermöglicht es, automatisch Muster zu erkennen und Anomalien in den Daten zu entdecken, die von intelligenten Sensoren und Geräten erzeugt werden - Informationen wie Temperatur, Druck, Luftfeuchtigkeit, Luftqualität, Vibrationen und Geräusche. Im Vergleich zu herkömmlichen BI-Tools können ML-Ansätze betriebliche Vorhersagen bis zu 20 Mal schneller und mit höherer Genauigkeit treffen.