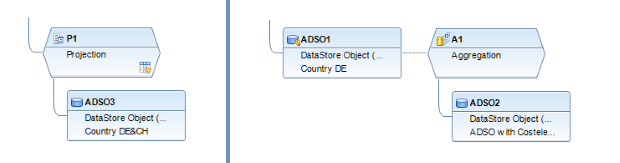
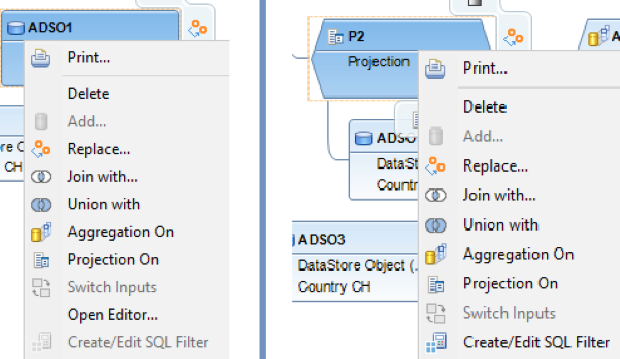
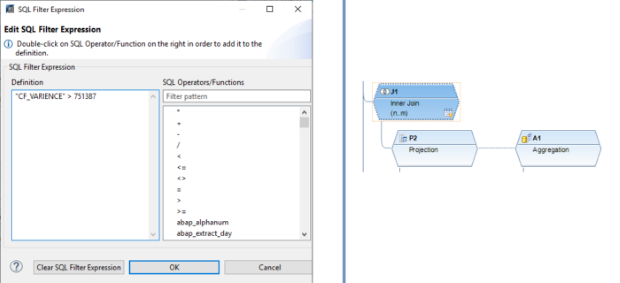
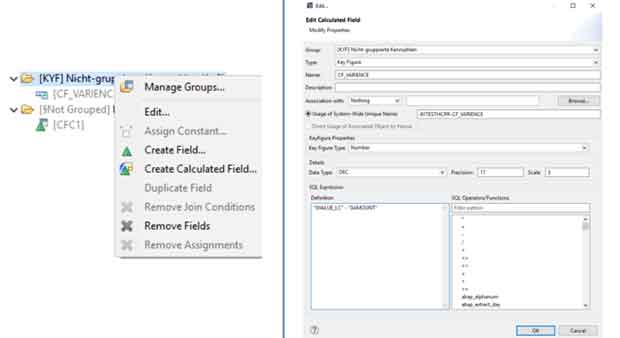
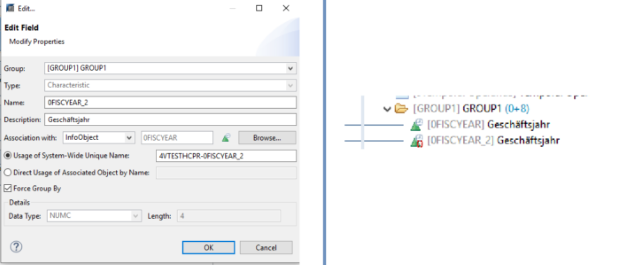
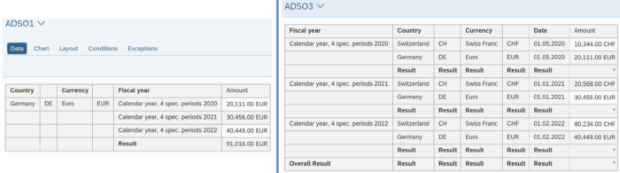
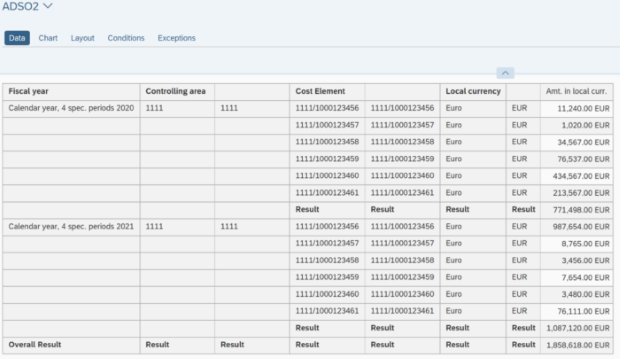
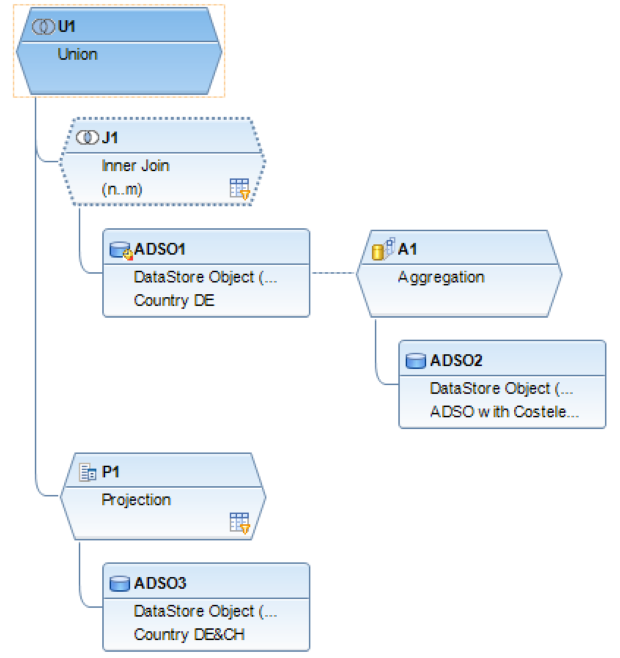
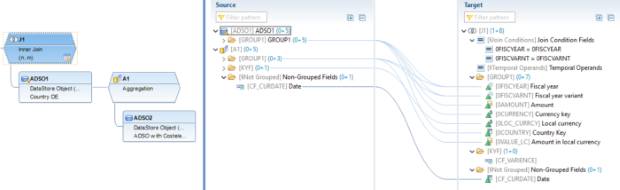
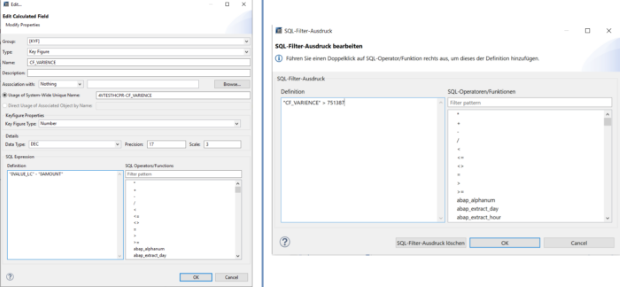
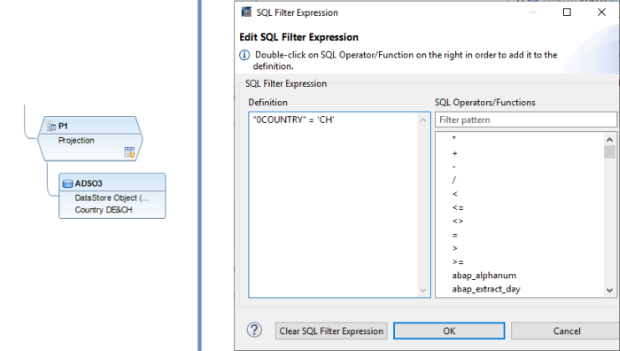
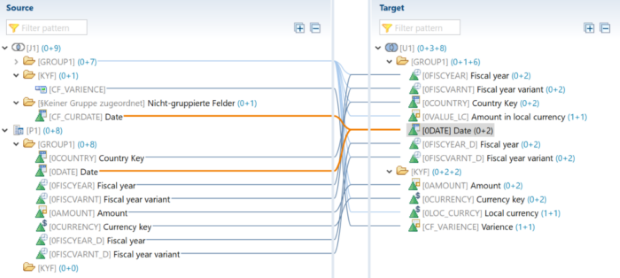
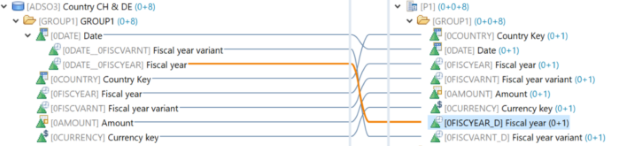
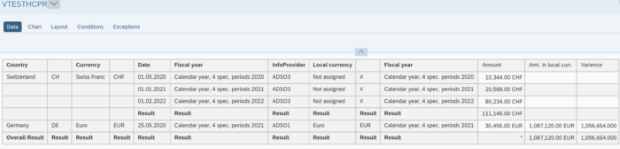
Il filtro SQL è un potente strumento che permette di filtrare dati specifici dall'intero CompositeProvider o dai suoi PartProvider. Permette di creare filtri aggiuntivi su diversi livelli di nodo di un CompositeProvider. Direttamente sul Top Node o sulle sue diverse parti, come ad esempio su specifiche Unioni, Giunzioni, Proiezioni e Aggregazioni sottostanti. Tuttavia, tali filtri non possono essere definiti direttamente su un PartProvider. Per questo motivo, è necessario aggiungere un nodo Aggregazione o Proiezione al di sopra di esso, per abilitare questa funzionalità. In un filtro SQL, sia i campi calcolati che i campi normali possono essere utilizzati per costruire un'espressione. A questo scopo viene utilizzato il linguaggio HANA SQL Script. Una volta selezionato, viene visualizzato un elenco di espressioni disponibili. Qui(apre una nuova finestra) è già disponibile un ampio riferimento a HANA SQL Script.