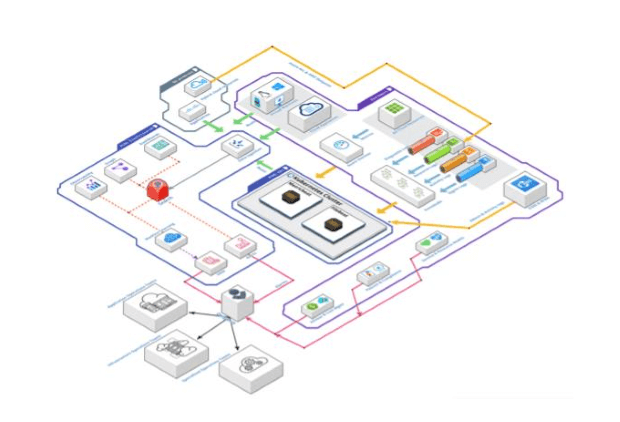
Il primo livello, la telemetria, si trova in alto a destra. Include fonti di dati provenienti dai nostri clienti cloud pubblici, come diversi tipi di log delle risorse cloud PaaS e SaaS, ad esempio i log delle attività o i log di login raccolti con EventHub, e le loro metriche raccolte da Azure Monitor. Inoltre, le risorse IaaS canalizzano le loro metriche e i loro log direttamente al nostro Elastic Stack utilizzando gli agenti Beats e raccolgono anche i protocolli di gestione e di attività delle offerte cloud O365 e M365 per fornire Resolution per l'osservazione e il monitoraggio del dominio del cloud workspace. L'ultima, ma non meno importante, è la tendenza a creare scenari ibridi, in cui i nostri clienti connettono i loro diversi cloud e impianti infrastrutturali del cloud. Raccogliamo protocolli e metriche di alcuni mezzi di esercizio, saltuariamente direttamente e saltuariamente tramite offerte cloud pubbliche come Azure Arc e AWS Outpost.