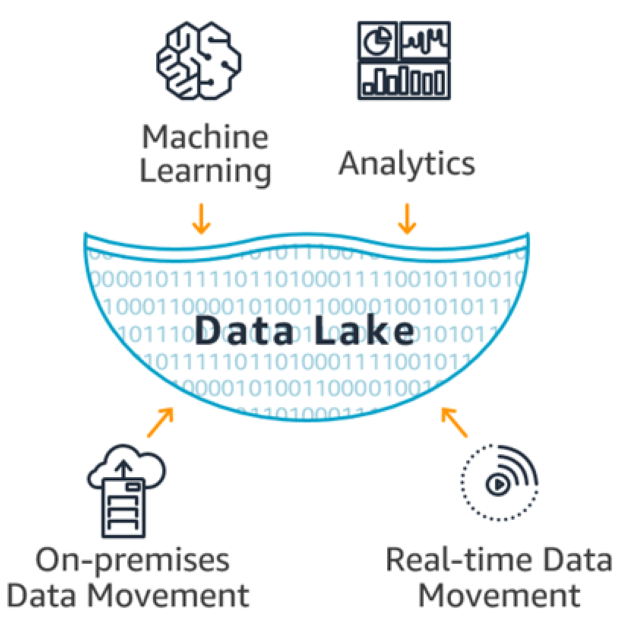
La tecnologia adottata dalle aziende per immagazzinare queste enormi quantità di dati di ogni tipo si è trasformata in un data lake. Questa tecnologia è in grado di archiviare qualsiasi tipo di dati, strutturati o non strutturati, nel loro formato grezzo. E questo grazie alla separazione tra i dati e lo schema che li definisce. (schema-on-read) [6]. Tradizionalmente, i dati aziendali vengono archiviati in sistemi di dati strutturati con uno schema che viene specificato durante l'acquisizione dei dati. D'altro canto, i data lake archiviano qualsiasi tipo di dati in formato grezzo per replicare i dati provenienti da fonti diverse che vengono successivamente pre-elaborati, aggregati, combinati e interpretati.
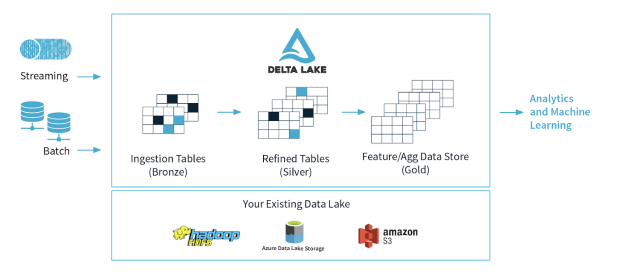
Un data lake progettato correttamente dovrebbe essere composto da tre aree principali. Queste sono Bronze (per clonare tutti i tipi di dati in formato grezzo), Silver (i dati vengono raffinati: pre-elaborati, puliti e filtrati) e Gold (combinati, aggregati per i benefici aziendali) [8]. Si potrebbero considerare ulteriori aree per separare altri processi specifici al tipo di azienda e ai requisiti. Le aziende stanno iniziando a rendersi conto dei problemi che si verificano con questo tipo di architettura basata solo sul Data Lake, per cui riscontrano una serie di problemi e sfide quando vogliono analizzare i dati o utilizzarli in report avanzati.
Il Data Lake non è progettato per supportare transazioni o metadati. Richiede una serie di competenze aggiuntive per eseguirle, gestirle e controllarle. I Data Lake non elaborano dati corrotti, incompleti o di bassa qualità. Inoltre, non sono progettati per combinare dati batch ed elaborazione in streaming. Non tengono conto delle diverse versioni dei dati o delle modifiche allo schema. Infatti, queste ultime possono rendere i dati completamente inutilizzabili. Inoltre, alcune organizzazioni hanno deciso di programmare regolarmente copie complete delle fonti di dati, consumando più risorse per archiviarle ed elaborarle.
La realtà attuale è che molti data lake sono diventati paludi di dati [11] per molte organizzazioni. Un luogo in cui coesistono tutti i tipi di dati senza che l'utente sappia cosa viene memorizzato e se la sua qualità corrisponde al contenuto delle fonti originali. Tutto questo rende la maggior parte dei data lake quasi inutilizzabili. La registrazione dei dati senza un processo di onboarding o una visione del loro potenziale utilizzo rende tutto ancora più difficile. Dal punto di vista dell'intelligenza artificiale e del ML, questi data lake, se utilizzati per creare modelli avanzati, diventano una fonte di garbage in / garbage out, come si dice in gergo. Inoltre, le aziende si sono rese conto che i dati presenti in questi sistemi crescono a un ritmo superiore a quello che i loro sistemi informatici sono in grado di analizzare.