Business Intelligence
La Federazione di Trino
Una risposta alle tensioni tra separazione e integrazione delle informazioni.
Da Joel Welti, Senior Data & Analytics Consultant
Business Intelligence
Una risposta alle tensioni tra separazione e integrazione delle informazioni.
Ebbene, Trino è un mezzo database, ecco cos'è. E sebbene molti lo considerino piuttosto strano e inutile, è proprio questo uno dei suoi maggiori punti di forza. Trino è un database in cui non vengono memorizzati dati. Per questo motivo, sul sito web non viene presentato come un database, ma come un programma di query SQL:
Trino è un motore di query SQL distribuito progettato per interrogare grandi insiemi di dati distribuiti su una o più fonti di dati eterogenee.
Ciò significa che Trino si comporta come un database, ma lo fa elaborando dati che sono memorizzati praticamente ovunque, tranne che al suo interno. Ecco perché è un database solo a metà. E questo è interessante, perché il classico database relazionale lavora quasi esclusivamente con i dati memorizzati al suo interno e i dati memorizzati sono accessibili esclusivamente tramite il suo software. Trino, invece, accede ai dati praticamente dappertutto (guarda il lungo e crescente elenco di connettori con altre tecnologie) e, in secondo luogo, questi dati possono essere recuperati direttamente da altri sistemi. Questo rende Trino ancora più integrato, ancora più inclusivo. Se disponi di due o più connettori per sistemi diversi, puoi anche "accedere ai dati di più sistemi all'interno di un'unica query". Ad esempio, puoi collegare i dati di log storici archiviati in un object store S3 con i dati dei clienti archiviati in un database relazionale MySQL". (trino.io) Si tratta della cosiddetta federazione di query (vedi il titolo di questo articolo). Non è una panacea e può avere un impatto sulle prestazioni delle query, che dipendono anche dal sistema di origine, ma a volte può essere una buona opzione.
Se torniamo indietro nella storia dell'informatica (analitica), ci rendiamo conto che il concetto di separazione tra archiviazione e calcolo per i database non è poi così nuovo. In effetti, questo concetto esiste da molto tempo, ma è diventato molto più importante nell'ambito dell'analisi, probabilmente a partire da Hadoop, che è stato rilasciato per la prima volta nel 2006.
Il nucleo di Apache Hadoop è costituito da una parte di archiviazione, nota come Hadoop Distributed File System (HDFS), e da una parte di elaborazione, che consiste in un modello di programmazione MapReduce.
I termini "calcolo", "elaborazione" e anche "esecuzione" sono sinonimi in questo contesto. Trino elabora i dati, come abbiamo già detto, ma i dati non vengono memorizzati in sé.
A differenza di Hadoop, Trino è decisamente e completamente SQL first. Il titolo del whitepaper originale è addirittura "Presto: SQL for everything". Aspetta, cos'è "Presto"? Presto è il nome originale del progetto che ora si chiama Trino. E qui c'è una triste storia da raccontare. Il progetto Presto è stato lanciato su Facebook nel 2014. Ma gli sviluppatori originali e Facebook si sono separati nel 2018 per questioni di gestione e controllo del progetto open source. Puoi trovare la lunga storia qui. In sostanza, ora esistono Trino e Presto, che sviluppano quasi lo stesso software in due progetti separati. Sebbene a volte il codice venga condiviso tra i due, questa divisione ha sicuramente ostacolato il progresso. Inoltre, sorge spontanea la domanda: quale dei due dovresti usare? Un chiaro caso di uguale eppure diverso. Possiamo confrontare l'impulso dei due repository su GitHub e concludere che il progetto Trino (con gli sviluppatori originali) è ancora più forte del progetto Presto (che Facebook ha trasferito alla Linux Foundation dopo le conseguenze). Ovviamente non si tratta di un dato scientifico molto preciso, ma se si considera il confronto tra chi usa Trino e chi usa Presto, la bilancia pende a favore di questo articolo su Trino.
Infine, è importante spiegare che Trino è stato progettato principalmente come database analitico. Ciò significa che nella maggior parte dei casi non è adatto all'elaborazione delle transazioni (OLTP).
Trino è stato sviluppato per il data warehousing e l'analisi: Analisi dei dati, aggregazione di grandi quantità di dati e creazione di report. Questi carichi di lavoro sono spesso indicati come Online Analytical Processing (OLAP).
Detto questo, torniamo indietro e confondiamo di nuovo le acque. Con l'ultimo formato di tabella per data lake, Apache Iceberg, l'OLTP per Trino è apparso all'orizzonte. Per saperne di più, leggi Apache Iceberg: A Primer on medium, The Definitive Guide to Lakehouse Architecture with Iceberg e Iceberg: ACID Transactions su min.io e anche questa introduzione ad Apache Iceberg in Trino su starburst.io. Tuttavia, dovresti procedere con cautela in questa direzione.
Ma seriamente, perché dovresti usare Trino? Perché dovresti usare un mezzo database che non è nemmeno in grado di memorizzare i dati?
1. There are already too many segregated information silos in organisations
Il fatto è che molto probabilmente la tua azienda non ha bisogno di un altro archivio dati segregato. Piuttosto ha bisogno di una migliore integrazione dei dati per avere un quadro completo. Le organizzazioni, man mano che crescono, sembrano gravitare verso innumerevoli silos di informazioni in modo "naturale". Le ragioni sono sia tecniche che organizzative. Qualunque sia la ragione, si tratta di un fenomeno diffuso e di un problema, come dimostra un articolo di Forbes. Tutto questo per dire che la segregazione (alias silos) sembra avvenire da sola, mentre per l'integrazione le organizzazioni devono impegnarsi attivamente. Vedi anche Silo Informationssilo (Wikipedia).
2. I database classici hanno solo i loro dati, e solo il loro motore di esecuzione siede su di essi
Questo è forse il motivo tecnico più importante per cui esistono così tanti silos di dati separati nelle organizzazioni. Il classico database relazionale è un silos di dati e non potrà mai essere altro. E se hai bisogno dei dati di un altro sistema, spesso non puoi accedervi senza copiarli e, a seconda della situazione, potresti dover acquistare un software diverso o addirittura affrontare un intero progetto ETL.
3. Flessibilità
Come abbiamo già stabilito, Trino si comporta come un database. Ma si collega alla maggior parte dei database relazionali tradizionali, nonché a Kafka e alle tecnologie data lake/cloud, tra le altre. Si collega anche (in modo semi-documentato) all'HTTP, quindi puoi interrogare un'API REST e collegare il risultato a qualsiasi cosa con una query SQL senza soluzione di continuità. A proposito di API REST: Naturalmente puoi collegarti tramite JDBC, ma Trino non è solo un client HTTP ma anche un server HTTP, vedi Trino REST API. In questo modo puoi effettuare una query direttamente dal browser senza dover interporre un server applicativo o simili.
Trino è quindi un ottimo strumento per l'integrazione dei dati. Ciò significa, ad esempio, che puoi creare l'intero processo ETL nel database. E poiché è compatibile con ANSI SQL, tutti i tuoi strumenti di BI possono essere collegati immediatamente.
Oh, e te l'ho già detto? Puoi anche renderlo un database in-memory: ecco il connettore.
4. Velocità e scalabilità
Trino is a highly parallel and distributed query engine, that is built from the ground up for efficient, low latency analytics. The largest organizations in the world use Trino to query exabyte scale data lakes and massive data warehouses alike. (trino.io)
Come si può scalare Trino? In poche parole:
1. Per il volume dei dati e l'IO:
Si scala il file system distribuito sottostante, come il già citato Hadoop Distributed File System (HDFS) o MINIO. A patto, ovviamente, che tu interroghi un connettore di data lake come Hive, Hudi o Iceberg. In caso contrario, dovrai scalare il sistema a cui ti stai collegando.
2. Per scalare il progetto:
Aggiungi altri lavoratori di Trino. Trino ha un coordinatore e molti lavoratori. Pensa a loro come a dei computer che dividono i compiti di grandi dimensioni in parti individuali per elaborarli in parallelo; alla fine il coordinatore mette insieme le parti e ti consegna il risultato.
5. Prezzi
Trino is open source and runs in the cloud or on-premise just like MINIO or HDFS. So, provided you know how to pull it off, you could get yourself something scalable for much cheaper than with the traditional vendors with licensing by the CPU Core or node or whatever. You might of course still require commercial licensing and enterprise support. There are options for this as well, for Trino from Starburst and for MINIO from MINIO themselves.
Questo articolo vuole cantare la canzone di Trino, ma ovviamente, dove c'è luce, ci sono anche ombre. Per brevità, citeremo qui solo le due peggiori:
1. Fino a poco tempo fa, le query fallivano semplicemente quando esaurivano la memoria. Ora esiste un'opzione di riversamento su disco. Ma non sempre funziona bene. (trino.io - Spill-to-Disk)
2. Attualmente un cluster può avere un solo coordinatore. Questo è un problema perché rappresenta un singolo punto di fallimento e perché finisce per limitare la scalabilità. Questo problema può essere risolto in una certa misura da elementi aggiuntivi nell'architettura, come i bilanciatori di carico. (Enabling Highly Available Trino Clusters - Goldman Sachs)
Il termine "data lake" ha diverse sfaccettature. Una di queste è che si tratta di un database, o più precisamente di un database che non richiede una corretta modellazione dei dati e dal quale poi si alimenta un data warehouse nel quale poi si fa pulizia. Ma non è questo il punto. Piuttosto, il moderno database analitico è modulare, come puoi vedere nella Figura 1. Il data lake è il livello più basso tra quelli attuali. Il data lake è il più basso dei quattro livelli attuali. Il formato della tabella è quello che ha preso forma più di recente.
Il motore di interrogazione (nel nostro caso Trino), che si aspetta un formato di tabella specifico (nel nostro caso Iceberg) in un formato di file specifico (nel nostro caso ORC), interroga la memoria dell'oggetto (nel nostro caso MINIO). Come riferimento, esistono diverse opzioni open source per ogni livello.
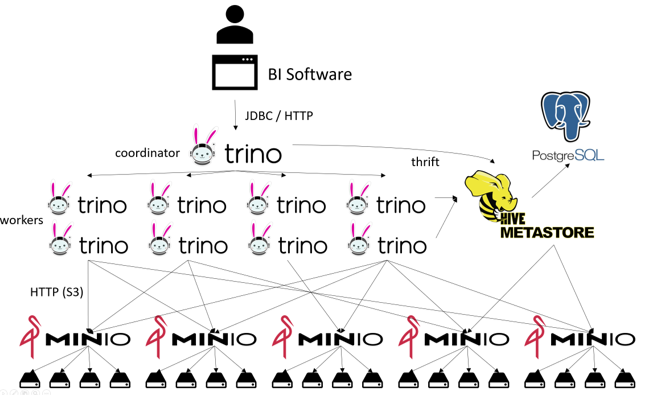
Figura 1: Gli strati di una struttura Trino
La tabella e il formato del file non sono elementi da installare, ma solo elementi che il motore di query deve comprendere (come ad esempio un connettore per Trino). I componenti di alto livello sono ancora quelli con cui abbiamo iniziato: La parte di archiviazione (Object Store) e la parte di elaborazione (Query Engine). Nella Figura 2, vediamo il tutto da una prospettiva di rete. Sì, mi piace disegnare linee e sì, ne ho dimenticate altre.
Figura 2: La rete di una configurazione Trino
Quindi, di cosa si tratta? L'utente si collega al coordinatore di Trino con il suo software di BI. Il coordinatore consulta il Metastore Hive (questo non è il motore di query della Figura 1, ma solo una piccola parte di esso, vedi La carriera solitaria del Metastore Hive su medium) per recuperare metadati, ad esempio sullo schema, sulle relazioni e sulla posizione dei dati. Il lavoro viene poi suddiviso in compiti individuali, che vengono distribuiti ai lavoratori. In parallelo, i lavoratori recuperano altri metadati per i loro compiti specifici dal metastore dell'alveare.
I lavoratori recuperano quindi i dati effettivi in parallelo dai nodi del file system distribuito ("data lake"), che a loro volta recuperano questi nodi in parallelo da diversi dischi rigidi.
E sì, per alcune operazioni il metastore interagisce direttamente con il file system distribuito. Inoltre, il metastore stesso è solo un software che a sua volta deve memorizzare i suoi dati da qualche parte, di solito in PosgreSQL. (Sì, parte di questo database è un altro database).
Ora diciamo: basta con le chiacchiere, diamoci da fare.
Questi sono gli ingredienti:
1. Ubuntu Linux
2. Docker
3. Postgres docker image: postgres:latest
4. MINIO docker image: minio/minio
5. Hive Metastore docker image: jiron12/hive-metastore
6. Trino docker image: trinodb/trino
wsl non è raccomandato. Se lavori in ambiente Windows, dovresti utilizzare Hyper-V:
Crea rapidamente -> Ubuntu 22.04 LTS
Se stai già lavorando con Ubuntu, puoi ovviamente saltare questo passaggio e ti salutiamo dal nostro mondo mortale.
Wenn du dein Ubuntu hast, öffne das Terminal, um Docker zu installieren, starte es und erstelle unser virtuelles Docker-Netzwerk, wir nennen es trino-cluster.
Ottieni l'ultimo container MINIO, eseguilo e connettilo alla nostra rete virtuale.
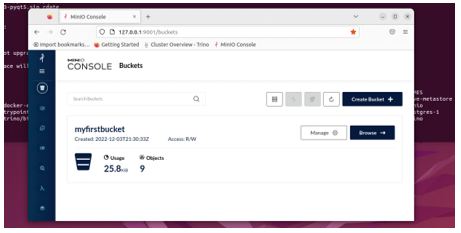
Non appena MINIO è in esecuzione (controlla con sudo docker ps -a), connettiti tramite il browser a 127.0.0.1:9001. Il nome utente e la password iniziali per il login sono minioadmin. Crea un bucket con il nome myfirstbucket.
Ottieni l'ultimo container MINIO, eseguilo e connettilo alla nostra rete virtuale.
Quindi connettiti alla tua nuova istanza PostgreSQL (ad esempio con DBeaver) e crea un database con il nome hive_metastore.
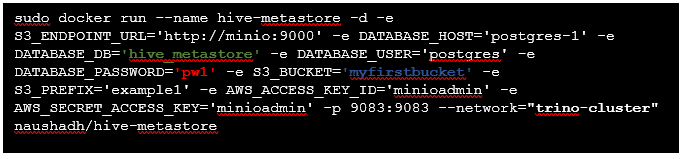
Ottieni e gestisci un container metastore Hive direttamente nella nostra rete virtuale.
Complimenti a naushadh per questo contenitore, che "funziona effettivamente come pubblicizzato con il minimo sforzo".
(hive-metastore/README.md - GitHub)
Infine, configuriamo Trino e lo aggiungiamo alla rete virtuale.
Se tutto è in funzione, dovresti avere lo STATO "Up" per ciascun contenitore quando
Poi vai al contenitore Trino che hai appena creato con
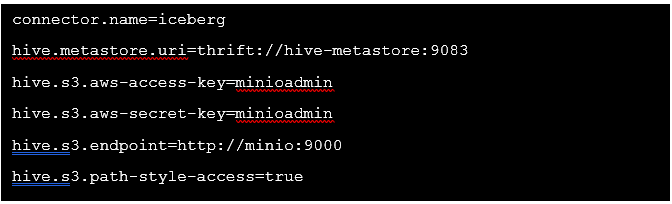
E crea un file /etc/trino/catalog/iceberg.properties con il seguente contenuto:
Quindi riavvia il contenitore Trino. Se ora ti connetti a Trino, dovresti essere in grado di creare uno schema come questo (sempre con DBeaver):
Potresti anche creare alcune tabelle. Quindi: verifica se ora hai dei dati nel tuo bucket MINIO.
Congratulazioni! Ora fai parte dell'esclusivo gruppo di persone che gestiscono una configurazione Trino. Questo significa che hai utilizzato le tecnologie cloud per creare un database distribuito in un data lake. Ora puoi giocarci quanto vuoi.
Naturalmente, ora abbiamo solo un nodo di archiviazione e un nodo di elaborazione. Questo funziona abbastanza bene, ma se vogliamo espanderlo, sono necessari altri passaggi. E ovviamente avremo bisogno di più hardware per avere un senso.
Abbiamo descritto cos'è Trino e poi abbiamo presentato Trino come un'ottima opzione per le moderne analisi dei big data. Abbiamo parlato di come le informazioni nell'impresa tendano a essere segregate, mentre ciò che vogliamo veramente è l'integrazione, e Trino lo fa molto bene. Ma, per tornare al titolo, proprio come nella costruzione di una nazione, l'integrazione può essere difficile anche nell'organizzazione aziendale. Dovremmo tutti impegnarci per ottenerla, ma a volte non possiamo andare fino in fondo per il momento. In questa tensione tra segregazione e integrazione, Trino ha una terza risposta: la federazione. Lascia i tuoi dati dove sono, nel sistema in cui sono cresciuti. Ma collegali comunque con tutti gli altri dati della tua azienda, in modo da poter lavorare con i tuoi dati come se fossero tutti in un unico posto.
Abbiamo poi discusso alcuni punti deboli di Trino. Poi abbiamo mostrato come possono essere i livelli di una configurazione di Trino e come si presenta di solito il paesaggio. Infine, abbiamo provato a configurare Trino per giocarci. Spero che ti sia piaciuto!
WSe a questo punto hai altre domande, non esitare a contattarci: Consulenza analitica e Business Intelligence | Swisscom
Se sei interessato a fornire consulenza ai nostri clienti su un'ampia gamma di tecnologie informatiche analitiche, dai un'occhiata alle nostre offerte di lavoro.

Senior Data & Analytics Consultant
Trova il lavoro o il mondo della carriera che fa per te. In cui vuoi contribuire a plasmare e sviluppare te stesso.
Ciò che ne fai è ciò che ci definisce.