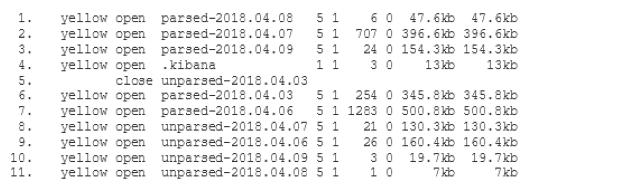
The old ELK service featured a filter which parsed log messages and
- extracted fields according to the Syslog protocol specification(opens in new tab)
- extracted messages containing JSON objects into fields according to the JSON attribute names
Furthermore, it featured a Curator (opens in new tab)configuration which ensured some periodical housekeeping in Elasticsearch. We will describe the details of configuring Curator in a future post, so please stay tuned for that.
Before we get started with the filter configuration, please note that you can find the templates for the config files presented below(opens in new tab) on Github. They are templates because you will have to replace certain parameters, like the Elasticsearch host name of your instance and the access credentials with the corresponding values from your own environment.
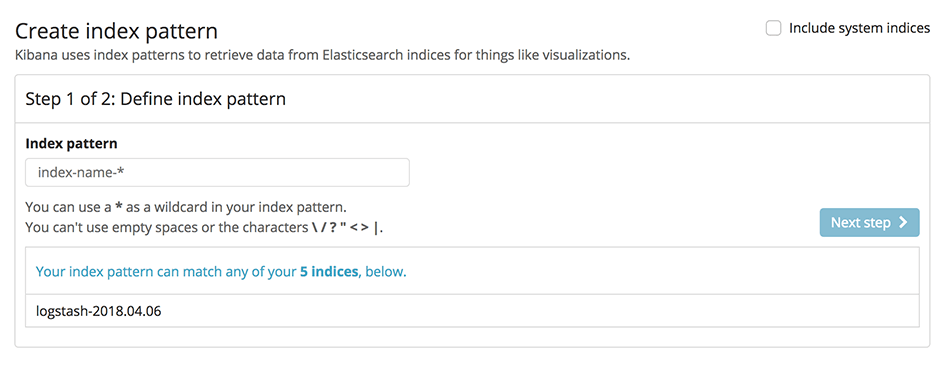
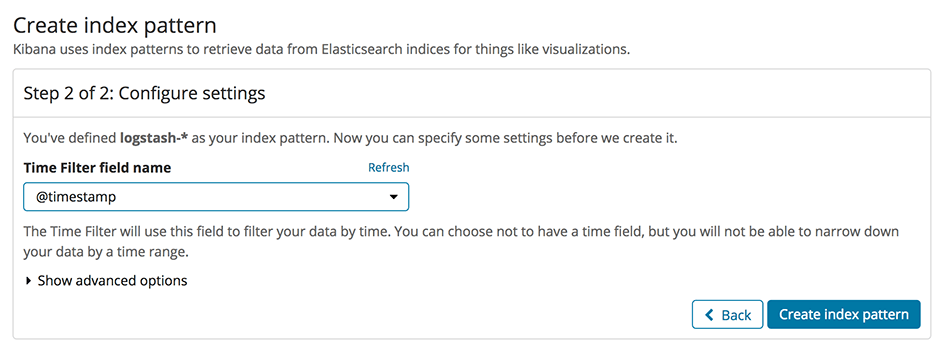
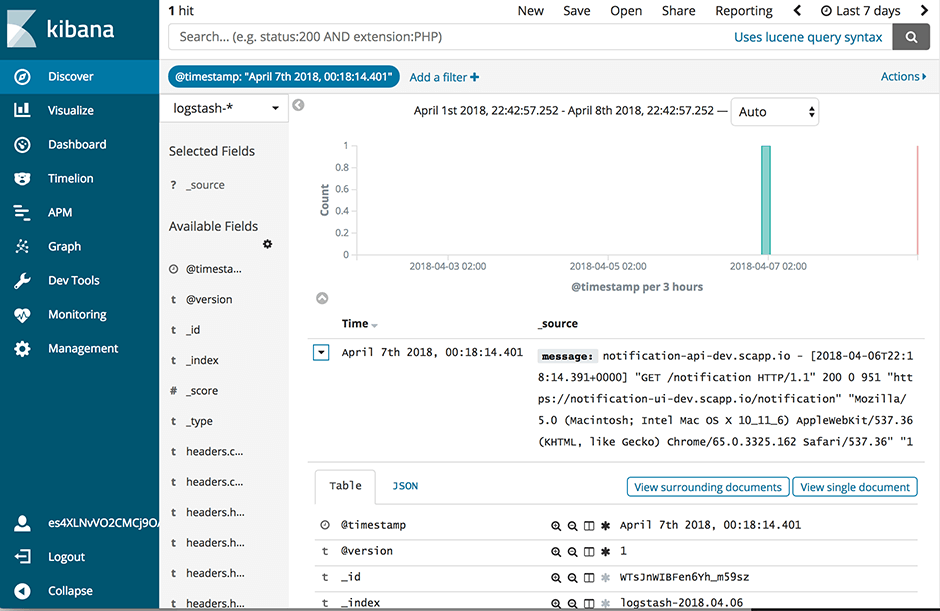
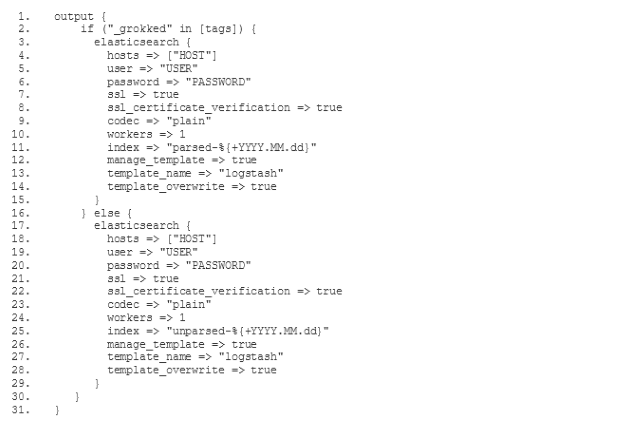
In order to configure our new ELK stack to process logs in the same way as the old ELK, we need to go for the mixed configuration mode described in the documentation of the Logstash buildpack(opens in new tab). In particular we need to specify our own filter and output configuration. For this purpose we add a two new subdirectories conf.d and grok-patterns to the directory where we have set up our Logstash configuration. Furthermore, we add the files filter.conf, output.conf and grok-patterns in these directories as follows: