Business Intelligence
The Federation of Trino
An answer for the tensions between information segregation and integration
By Joel Welti, Senior Data & Analytics Consultant
Business Intelligence
An answer for the tensions between information segregation and integration
Well, Trino is half a database, that’s what it is. And while many might consider that pretty strange and useless for now, exactly this is one of its main strengths. Trino is a database with no data based in it, that’s also why its website introduces it not as a database, but as an SQL query engine:
Trino is a distributed SQL query engine designed to query large data sets distributed over one or more heterogeneous data sources.
What this means is that Trino behaves like a database, but it does that, processing data stored pretty much anywhere but within itself. That’s why it’s only half a database. And this is interesting because the classical relational database operates nearly exclusively on data stored within itself and the data stored within it is accessed exclusively through its own software. Trino firstly accesses data nearly anywhere (Have a look at the long and growing list of connectors to other technologies), and secondly, this data can also be accessed directly by other systems. This makes Trino more integrated, even in fact integrative. When you have two or more connectors to different systems you can also “Access data from multiple systems within a single query. For example, join historic log data stored in an S3 object storage with customer data stored in a MySQL relational database.” (trino.io) This is what’s called Query Federation (see the title of this piece). This is not a silver bullet, it can come with query performance impact, depending also on the source system, but it can certainly sometimes be a great option.
Now, when we go back in the history of (analytical) IT, we first note, that this concept of separation of storage and computation for databases is not exactly new at all. In fact, it goes way back, but it has become much more prominent in analytics, probably starting with Hadoop, which was initially released in 2006.
The core of Apache Hadoop consists of a storage part, known as Hadoop Distributed File System (HDFS), and a processing part which is a MapReduce programming model.
The terms “computation”, “processing” and also “execution“ are synonymous in this context. Trino, as we have mentioned, processes data, but data is not stored within itself.
Now, as opposed for example to Hadoop, Trino is definitely and comprehensively SQL first. In fact, the title of the original whitepaper is “Presto: SQL on Everything”. Wait, what’s “Presto”? Presto is the original name of the project that is now Trino. And there is a sad story to be told here. The Presto project was started at Facebook in 2014. But the original developers and Facebook split in 2018 over questions of management and control over the open-source project. The long story is here. Essentially there is now Trino and Presto, which in two separate projects, develop nearly the same software. And while sometimes code is shared between the two, this split has almost certainly hampered progress. Also, of course, the question arises: Which one to use? A clear case of same same but different. We can compare the pulse of the two repos on GitHub and conclude that the Trino project (with the original devs) is still going stronger than the Presto project (which Facebook after the fallout transferred to the Linux Foundation). This is not the most exact of sciences obviously, but together with a comparison of Who uses Trino and Who uses Presto, this is at least what tipped the balance toward this article being about Trino.
Lastly, it is important to declare that Trino first of all was designed as an analytical database. This means that in most cases it will not be well suited for transactional processing (OLTP).
Trino was designed to handle data warehousing and analytics: data analysis, aggregating large amounts of data and producing reports. These workloads are often classified as Online Analytical Processing (OLAP).
Having stated that clearly, let’s turn right around and muddy the waters again. With the newest data lake table format, which is Apache Iceberg, OLTP has appeared on the horizon for Trino. Read more about that in Apache Iceberg: A Primer on medium, in The Definitive Guide to Lakehouse Architecture with Iceberg and Iceberg: ACID Transactions each on min.io and also in this Introduction to Apache Iceberg In Trino on starburst.io. Still, proceed with caution in that direction.
But now for real, why you would want to use Trino? Why would you want to use half a database, in fact, one that cannot even store data in it?
1. There are already too many segregated information silos in organisations
The matter of the fact is that your organization most likely does not need another segregated data store. Much rather it needs better data integration to get the full picture. Organizations, as they are growing, seem to gravitate towards countless information silos “naturally”. There are technical as well as organizational reasons for this. Whatever the reason, it is widespread and it is a problem, here is just one article in Forbes about it. All this to say: The segregation (aka silo-ing) seems to happen all by itself, as for integration, organizations have to make an active effort. See also Information Silo (Wikipedia).
2. Classical Databases have only their data, and only their execution engine sits on top of it
This might just be the main technical reason, as for why organizations are full of segregated data silos. Your classical relational database is a data silo, and it’s all it will ever be. And when you need the data in some other system as well, you will often be unable to access it without copying it and depending on the situation you will buy another software for that, maybe you will even have a whole ETL project at your hands.
3. Flexibility
Trino, as we have already established, behaves like a database. But it connects, among many others, to most of the traditional relational databases, as well as Kafka and data lake/cloud technologies. It (kind of semi-documented) even connects to HTTP, so you can query a REST API and join the result with anything you like in one seamless SQL query. Talking about REST API’s: While of course you can connect by JDBC, Trino is not only an HTTP client it is also an HTTP server, see the Trino REST API. So, you could query it right out of the browser, no application server or the like needed in between.
So Trino is a great tool for data integration. Meaning, for example, you could create your whole ETL process in-database. And because it is ANSI SQL compliant all your BI tools can connect right away.
Oh, and have I already mentioned? You can also make it an In-Memory database, here is the connector.
4. Speed and Scalability
Trino is a highly parallel and distributed query engine, that is built from the ground up for efficient, low latency analytics. The largest organizations in the world use Trino to query exabyte scale data lakes and massive data warehouses alike. (trino.io)
How does Trino scale out? Well in a nutshell:
1. For data volume and IO:
You scale the underlying distributed filesystem like for example the Hadoop Distributed File System (HDFS) we already mentioned or MINIO. This is, provided of course, you query a data lake connector like Hive, Hudi or Iceberg. Otherwise, you have to scale whatever system you are connecting to for this.
2. For scaling execution:
You add more Trino workers. Trino has one coordinator and many workers, think of them as computers that split large tasks into separate parts to work on them in parallel, and at the end, the coordinator puts the pieces together and hands the result back to you.
5. Pricing
Trino is open source and runs in the cloud or on-premise just like MINIO or HDFS. So, provided you know how to pull it off, you could get yourself something scalable for much cheaper than with the traditional vendors with licensing by the CPU Core or node or whatever. You might of course still require commercial licensing and enterprise support. There are options for this as well, for Trino from Starburst and for MINIO from MINIO themselves.
This article is about singing the song of Trino, but of course, where there is light there are also shadows. For brevity let’s mention the two most serious ones here:
1. Up until recently queries when they ran out of memory simply failed. Now there is a spill-to-disk option. But it does not always work very well. (trino.io - Spill-to-Disk)
2. A cluster can currently only have one coordinator. This is bad because it is a single point of failure and also because at some point it will start to limit scalability. This problem can to some degree be overcome, with additional elements in the architecture e.g. load balancers. (Enabling Highly Available Trino Clusters - Goldman Sachs)
There term data lake has some different factettes. One of them is that it is a database, more exactly finally one where correct data modeling does not really matter, and then from that, you feed a data warehouse where you then clean the mess up. That’s not what this is about. Rather the modern analytical database is modularized as you can see in Figure 1. The data lake is its lowest of currently four layers. The Table Format is the one that fully took shape latest.
The Query Engine (Trino in our case), expecting a certain Table Format (Iceberg in our case), within a certain File Format (ORC in our case), queries the Object Store (MINIO in our case). For reference, there are some different open-source options for each layer.
Figure 1: The layers of a Trino setup
Now, the table format and the file format are nothing that you have to install they are just things the query engine has to understand (like having a connector for it, in the case of Trino). The high-level components are still the ones we started out with: The storage part (object store) and the processing part (query engine). Next, let’s look at it from a more network-like perspective in Figure 2. Yes, I like to draw lines, and yes, I still forgot some.
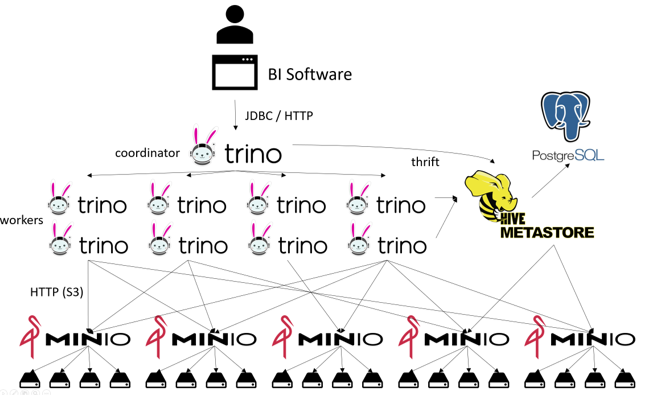
Figure 2: the network of a Trino setup
So, what are we looking at here? The user with their BI software connects to the Trino coordinator. The coordinator looks into the Hive metastore (this is not the query engine from Figure 1, rather just a small part of it, see The Solo Career of Hive Metastore on medium) to fetch metadata e.g. about schema, relations, and whereabouts of the data. It then breaks up the work into distinct tasks which are distributed among the workers. The workers in parallel fetch more metadata related to their specific tasks from the Hive metastore.
The workers then, in parallel, fetch the actual data from nodes of the distributed filesystem (“data lake”) these nodes in turn fetch in parallel from multiple disks.
And yes, for some operations the metastore interacts directly with the distributed filesystem. Also, the metastore itself is just a software, which in turn has to persist its data somewhere, typically in PosgreSQL. (Yes, a part of this database is another database)
Now we say, enough of the talking, let’s get it done.
These are the ingredients:
1. Ubuntu Linux
2. Docker
3. Postgres docker image: postgres:latest
4. MINIO docker image: minio/minio
5. Hive Metastore docker image: jiron12/hive-metastore
6. Trino docker image: trinodb/trino
wsl not recommended. If on Windows you might want to use the Hyper-V:
Quick Create -> Ubuntu 22.04 LTS
If you are already on Ubuntu, you can of course skip this step, and we salute you from our mortal world.
When you have your Ubuntu, open the terminal to install docker, start it, and create our virtual docker network, we will call it trino-cluster.
Get and run the latest MINIO container and connect it to our virtual network.
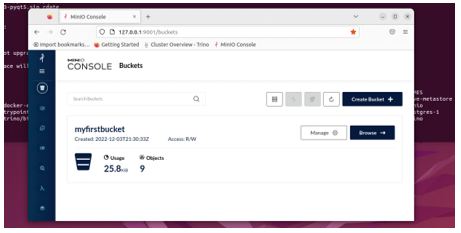
As soon as MINIO is running (check with sudo docker ps -a) connect to it through the browser at 127.0.0.1:9001. For logging in, initial username and password are minioadmin. Once there, create a bucket with the name myfirstbucket.
Get and run the latest Postgres container and connect it to our virtual network.
Then connect to your new PostgreSQL instance (for example using DBeaver) and create a database with the name hive_metastore.
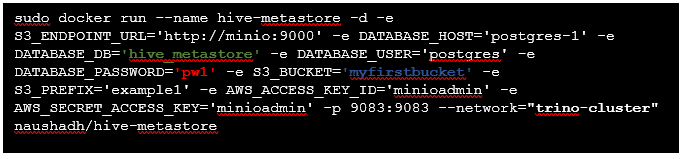
Get and run a hive metastore container right within our virtual network.
Props to naushadh for this container which "actually works as advertised with minimal bloat".
(hive-metastore/README.md - GitHub)
Finally, we get Trino itself up and add it to the virtual network.
If everything runs you should have STATUS “Up” for each of the containers when running
Then go into the Trino container just installed by
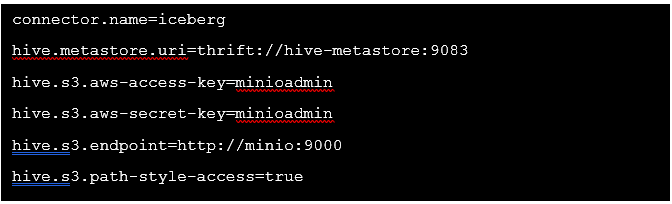
And create a file /etc/trino/catalog/iceberg.properties with the following content:
After this restart the Trino container. Now when you connect to Trino you should be able to create a schema like this (again, for example with DBeaver):
Maybe you even want to create some tables. Afterwards: Check back and see if you now have some data in your MINIO bucket.
Congratulations! You now belong to the very exclusive group of people who run a Trino setup. This means you have leveraged cloud technologies to create a distributed database on a data lake. You can now play with it, according to your heart’s desire.
Of course, we only have one storage and one processing node by now. This works just fine but scaling this out would involve a few more steps. And of course, would also need some more hardware to run it on, for that to make sense.
We have described what Trino is and then made a case for Trino as a great option for modern big data analytics. We have talked about how information in the organization seems to tend towards information segregation, when in fact we want integration, Trino is very good with that. But, coming back to the title, just like in nation building, integration, also in the business organization can be hard. We should all strive for it, but sometimes, for the time being, we cannot go all the way there. And in this tension between segregation and integration, Trino also has a third answer: The federation. Leave your data where it is, in the system, it grew up in. But still connect it with all the other data in your business, allowing you to work with your data as if it was all together in one place.
We have also touched on some weaknesses of Trino afterwards. We have then shown what the layers of a Trino setup can be, and what its landscape typically looks like. Finally, we took a shot at setting up Trino to play with it. I hope you enjoyed!
If you have more questions at this point, feel free to contact us: Analytics consulting and business intelligence | Swisscom
Also, if you are interested in consulting our customers about a broad range of analytic information technology, have look at our job openings.

Senior Data & Analytics Consultant
Find the job or career world that suits you. In which you want to help shape and develop yourself.
What you make of it is what defines us.