Machine Learing
Machine Learning on the Edge
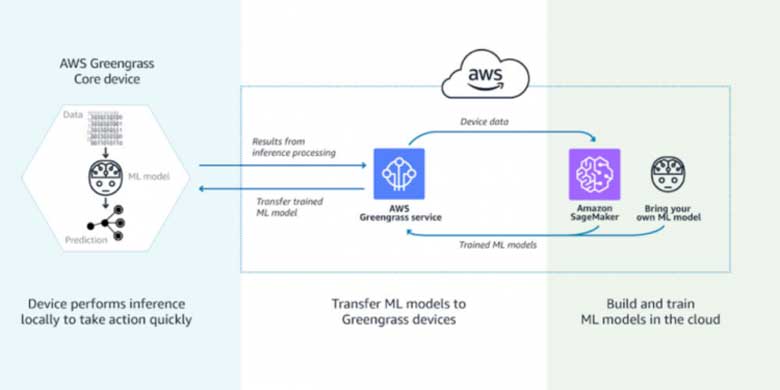
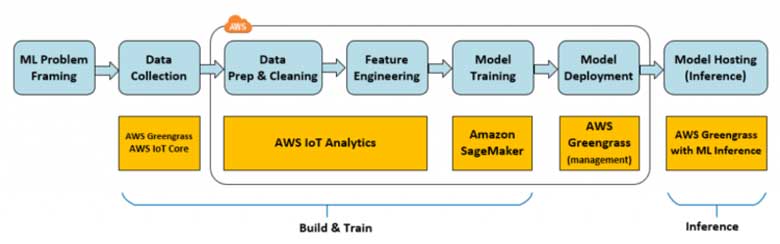
According to a Gartner study artificial intelligence (AI) will be the No. 1 trend in coming 5 years in IoT. The number of IoT devices will increase from 14.2 billion in 2019 to 25 billion in 2021. The value of AI in this context is its ability to quickly gaining insights from devices data. Machine learning (ML), an AI technology, brings the ability to automatically identify patterns and detect anomalies in the data that smart sensors and devices generate - information such as temperature, pressure, humidity, air quality, vibration, and sound. Compared to traditional BI tools the ML approaches can make operational predictions up to 20 times faster with greater accuracy.